
科大携手字节跳动发布 BindWeave,让视频生成精准“锁定”主体
![]() 前沿资讯
1762339970更新
前沿资讯
1762339970更新
![]() 0
0
导读: 中国科学技术大学与字节跳动联合研发的 BindWeave 框架,不仅可以让视频主体始终一致,还能应对多主体、多场景互动,实测效果碾压现有开源和商业产品。
视频生成技术发展迅猛,但想同时兼顾主体与场景仍是难题。现有模型容易出现五官变形、物体大小不稳、动作逻辑错乱等问题。
针对这一痛点,中科大和字节跳动团队联合推出了 BindWeave 框架。其核心思路是:先让一个“多模态大脑”理清文字指令与参考图的逻辑,再生成视频。
具体做法是,BindWeave 配备了 智能指令解析器,利用多模态大语言模型(如 Qwen2.5-VL)将文字和参考图整合为统一序列。
例如输入“男人在厨房用勺子炒菜”,模型先识别出主体、动作、场景及空间关系,生成“主体感知隐藏状态”,再通过“连接器”与扩散 Transformer(DiT)特征对齐,同时加入 CLIP 和 VAE 特征,保证视频既像参考图,又符合指令逻辑。
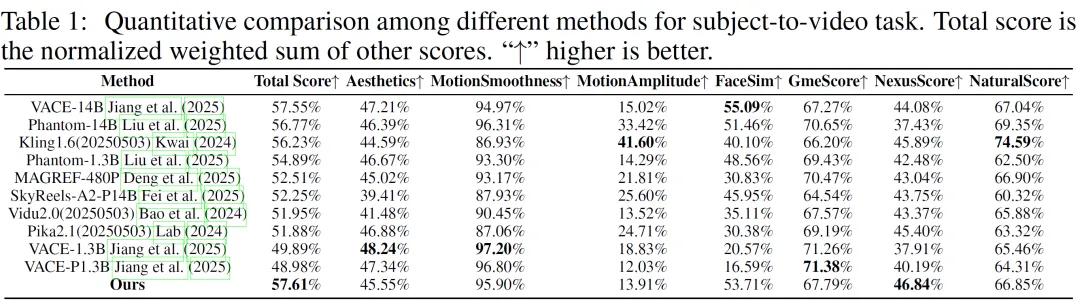
实测结果显示,BindWeave 在 OpenS2V-Eval benchmark 测试中表现突出。该评测包含 180 条指令,覆盖单主体、多主体及人机互动等场景,衡量指标包括主体一致性(NexusScore)、自然度(NaturalScore)、文字视频匹配度(GmeScore)等。BindWeave 不仅在总分上遥遥领先,NexusScore 高分尤其说明主体不变形的表现十分稳健。
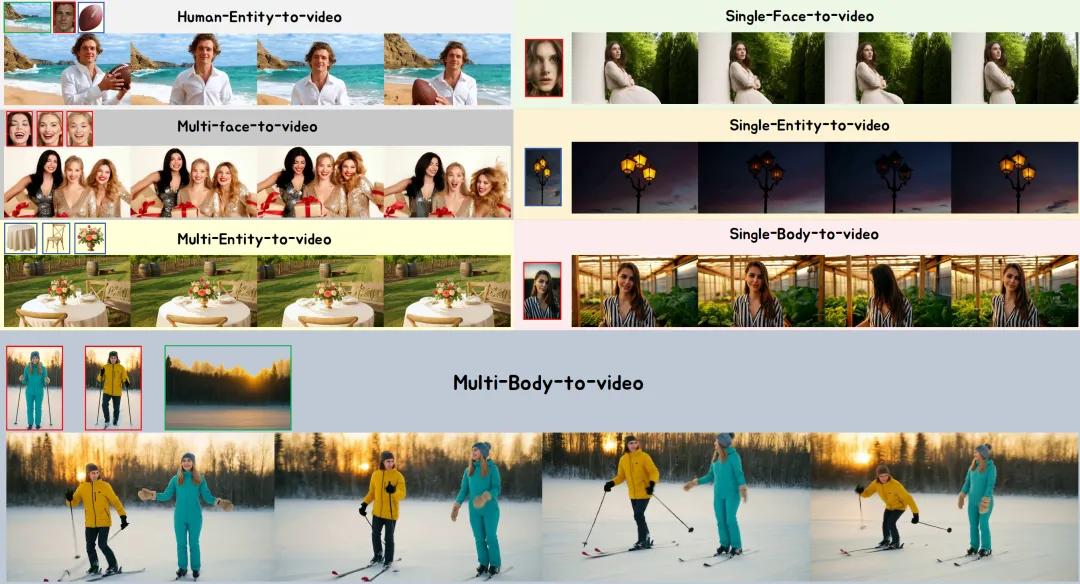
在实际场景中,优势更加明显:
- 单物体场景:如生成“篮球鞋在球场上运动”,BindWeave 能保留鞋底纹理和起跳弯曲动作,而其他模型可能丢失细节。
- 多主体场景:如“人在厨房用 wok 炒蔬菜,加酱油”,BindWeave 准确呈现“加酱油”动作,保持蔬菜颜色和炒锅外观,而其他模型常出现物体缺失或动作错误。
目前,BindWeave 支持 1-4 张参考图输入,50 步即可生成视频,同时训练数据来源于 OpenS2V-5M,经过 100 万组视频-文字对训练,并采用“小范围稳定→大规模提升”的两阶段策略,保证稳定性与泛化能力。
HuggingFace 链接:https://huggingface.co/ByteDance/BindWeave
 豫公网安备41010702003375号
豫公网安备41010702003375号