
火山引擎发布豆包语音识别模型2.0:听得更准、看得更清、还能靠逻辑判断词义
![]() 工具推荐
1764925090更新
工具推荐
1764925090更新
![]() 0
0
导读:火山引擎发布新一代“豆包语音识别模型2.0”,识别更准、能看图、还能推理上下文,多音字、人名地名都能判断到位,并支持 13 种海外语种,让语音输入更贴近“能听懂人话”的使用体验。
12 月 5 日,火山引擎宣布推出全新的豆包语音识别模型 2.0。这次升级,给语音输入加上了“理解能力”:不仅能听清每个字,还能结合上下文推断用户真正想说什么。整体关键词召回率提升 20%,多模态识别也正式加入。

过去,系统想要识别精准,都需要依赖历史词汇或者预设词库,一旦遇到生僻地名、人名、多音字,就容易跑偏。
豆包语音识别 2.0 的做法进行了升级,它会结合当前对话的语境自行判断。例如,在讨论苏辙生平时,用户突然说出“筠州”。即便“筠州”没在前文出现,它也能根据“正在聊苏轼、苏辙”这一背景,把“筠州”和其他同音地名区分开,实现正确识别。
另一个明显的升级,是加入了视觉内容解析,让语音识别能真正“看图说话”。
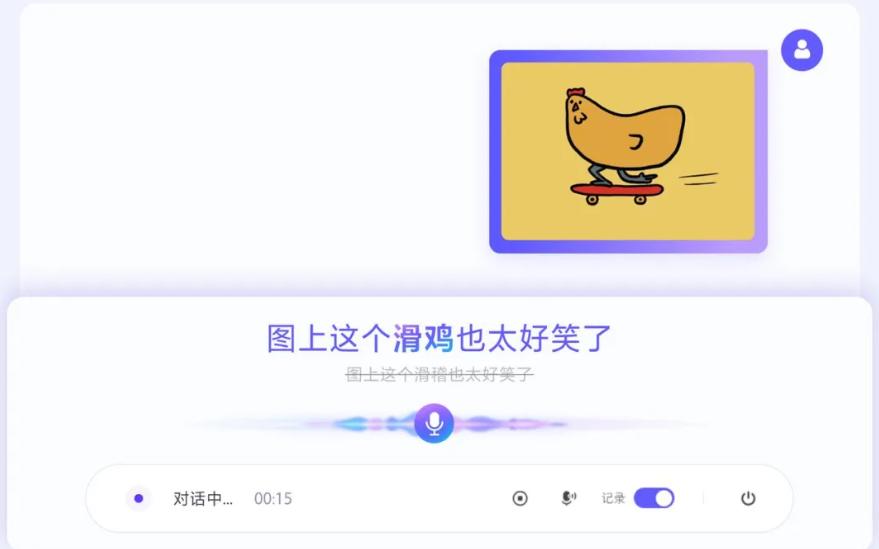
在搜拍等场景中,用户往往会一边看图,一边用语音描述内容。这时,传统系统容易把不常见的词听错,比如“滑鸡”常会被识别成“滑稽”。豆包语音识别 2.0 会同步理解图像内容:如果照片里确实是一只玩滑板的鸡,就不会把用户的描述听成别的词。
在图片创作场景中,用户常用语音来描述想修改的元素,比如“把马头改小一点”。如果只听语音,很可能被误解成“码头”。结合图像后,它能精确判断用户说的是画面里的“马头”,避免出现偏差。
豆包语音识别 2.0 在保持中英及方言识别精准度的同时,还进一步拓展了多语种能力,目前支持 日语、韩语、德语、法语、西班牙语、印尼语、葡萄牙语等共 13 类语言。让跨境客服、海外内容制作、直播场景等,都能更方便地接入语音识别服务。
目前,豆包语音识别 2.0 已在火山方舟体验中心上线,并向企业提供 API 服务。官方表示,后续将在多模态与多场景方向持续增强识别能力,为更多业务提供快速、精准的语音转文字服务。
参考资料:https://mp.weixin.qq.com/s/U3OyDRFXElPbl0EIaBfUGA
 豫公网安备41010702003375号
豫公网安备41010702003375号