
LFM2-2.6B-Exp引热议,实验版本小模型“越级发挥”
![]() 前沿资讯
1766732735更新
前沿资讯
1766732735更新
![]() 0
0
导读:Liquid AI 推出基于纯强化学习训练的 LFM2-2.6B-Exp,引发社区强烈反响。这个仅 2.6B 参数的开源模型,在指令和数学等评测中表现突出,甚至在部分指标上超过体量大得多的模型。
Liquid AI 最新发布的 LFM2-2.6B-Exp,正在社区里引发不小的讨论。
从官方披露的信息来看,LFM2-2.6B-Exp 目标非常聚焦:明确针对指令跟随、知识理解和数学能力进行训练。也正因为这种取舍,使其在多个相关基准测试中表现持续提升,在 3B 级别模型中处于领先位置。
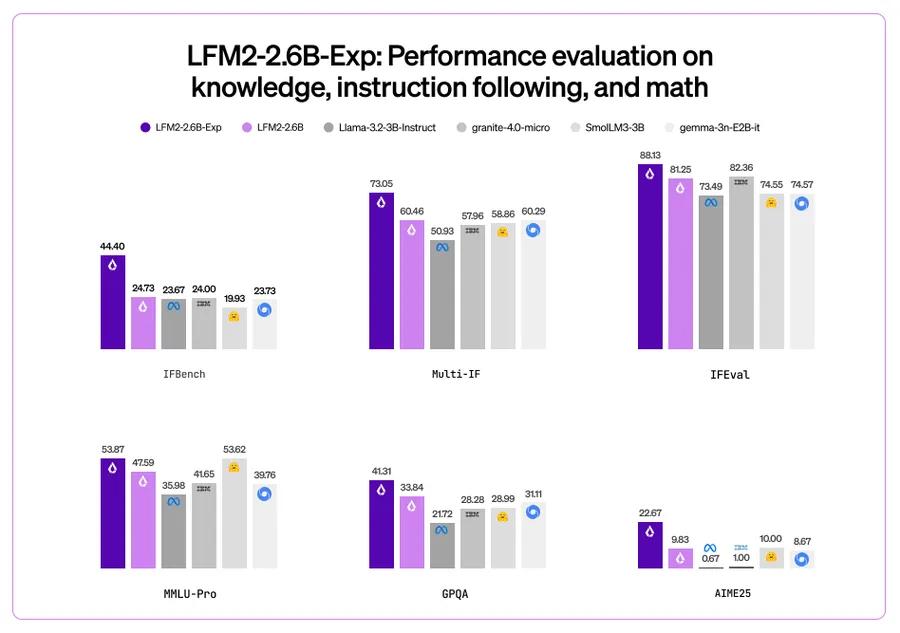
最受关注的,是其在 IFBench 上的表现。在这一指标上,该模型超过了 DeepSeek R1-0528,而 R1 的参数规模约为其 263 倍。这一结果公布后,很快在开发者社区引发讨论。
有网友直言,这种对比“让人很难不震惊”。有人将它与早期 ChatGPT 的升级时刻类比,认为这是又一次刷新认知的节点:“一个只有 2.6B 参数、可以在手机上运行的开源模型,某些方面已经超过了早期的大模型,这本身就很不可思议。”
也有声音把视角放得更远。部分开发者认为,如果在通用智能之后,能力能够持续向小模型下沉,那么在任何设备上运行高性能模型并非遥远设想。在他们看来,LFM2-2.6B-Exp 更像是一次提前到来的信号,指向“小而强”的另一条路径。
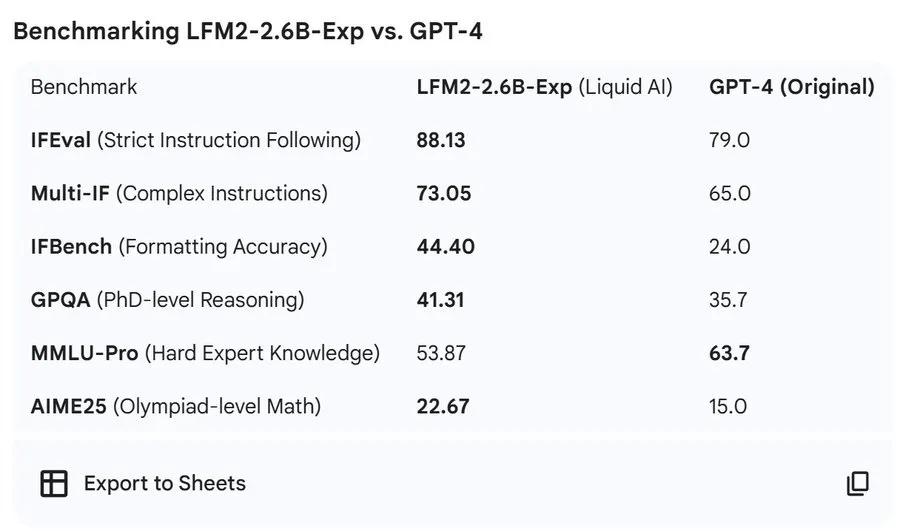
还有网友注意到更具体的数据点:2.6B 参数规模下,在 GPQA 上拿到 41.31% 的成绩,相比之下,GPT-4 得分为 35.7!在评论区,这被形容为“离谱”“疯狂”,甚至有人感叹,这样的小模型已经具备相当扎实的知识理解能力。
回到官方定位,由于模型体量较小,Liquid AI 推荐在具体、垂直的任务中进行微调,以释放最大性能潜力,例如代理式任务、结构化数据抽取、RAG 场景、创意写作和多轮对话等。
相对应地,对于高度依赖庞大外部知识、或需要复杂编程能力的任务,并不推荐直接使用该系列模型。
从架构层面看,LFM2 系列采用的是短卷积与注意力机制结合的混合结构,在有限参数规模下,兼顾了上下文建模能力和推理效率。模型统一支持 32K 上下文长度,并覆盖包括中文在内的多种语言。
整体来看,LFM2-2.6B-Exp 更像是一场方向明确的实验:不靠堆参数,而是通过训练方式和目标设计,探索小体量模型的性能边界。
项目地址:https://huggingface.co/LiquidAI/LFM2-2.6B-Exp
 豫公网安备41010702003375号
豫公网安备41010702003375号