
“小钢炮”来了!英伟达开源Nemotron 3 Nano:30B参数只打3B火力,速度狂飙3倍
![]() 前沿资讯
1766918131更新
前沿资讯
1766918131更新
![]() 2
2
导读:英伟达甩出Nemotron 3 Nano:30B参数只激活3.2B,跑得比同体量对手快3.3倍,1M长上下文、工具调用、数学代码全线拉满,还直接把模型+数据+训练配方全部开源。小而快的时代,真的来了。
英伟达低调挂出技术报告:Nemotron 3 Nano 30B-A3B正式发布,开源!
传统思路的“越大越强”被它直接掀桌。总量31.6B的“身材”,每次推理只唤醒3.2B(含嵌入3.6B)。实测在8K输入+16K输出场景里,推理速度是Qwen3-30B-A3B的3.3倍,GPT-OSS-20B的2.2倍,一张H200就能起飞。
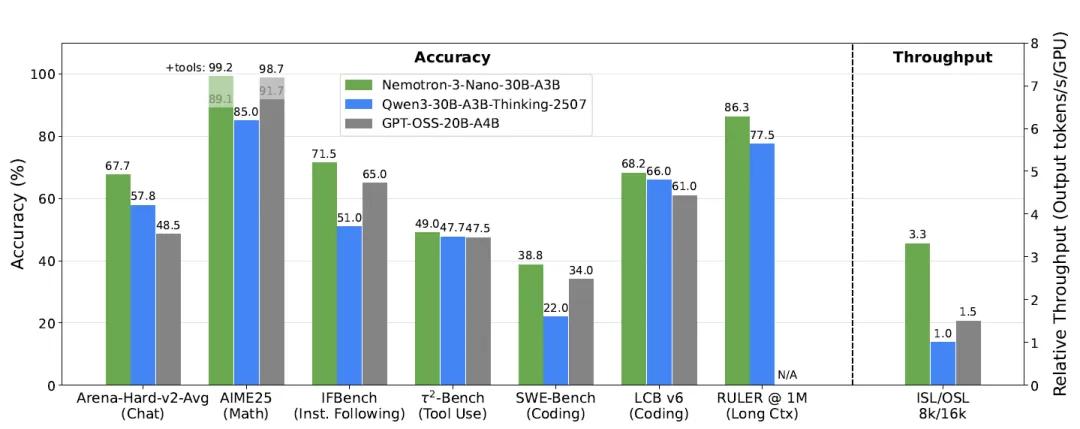
长上下文不再是“噱头”。通过连续预训练+256k合成检索数据,Nemotron 3 Nano把窗口直接推到100万token,在RULER 1M基准上86.3分,甩开对手近10分,长文摘要、跨文档问答、代码库级理解稳稳拿捏。
数学、代码、工具调用,全能“三栖”
- AIME25数学竞赛:无工具89.1分,开Python工具直接飙到99.2分,差0.8就满分。
- LiveCodeBench代码实战:68.3分,比Qwen3高2分,比GPT-OSS高7分。
- SWE-Bench软件工程:38.8分,开源模型第一梯队,能自己修GitHub真实Issue。
- 工具调用:BFCL v4 53.8分,airline、retail、telecom三大场景平均49分,订机票、查账单、解纠纷一条龙。
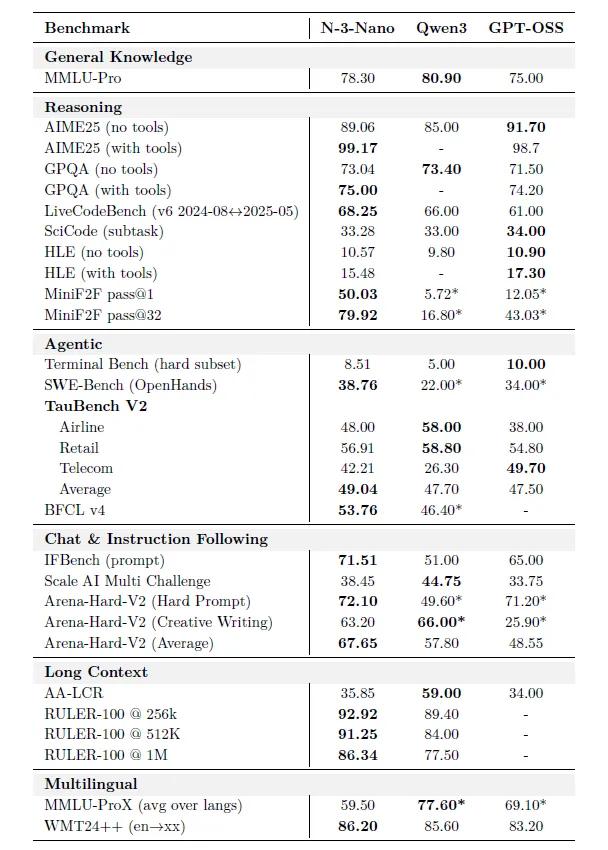
FP8量化,速度再提30%,精度几乎不掉。用选择性量化保下6层注意力+6层Mamba的精度,其余全部压成FP8,AA-LCR、MMLU-Pro等12项基准平均掉分不到1%,吞吐量却再涨30% ,边缘端也能跑得欢。
预训练阶段,开发团队烧了25T token,其中2.5T全新英文网页、428B代码、31.7B STEM推理问答全部上架HuggingFace。更狠的是,代码转译、跨学科合成题、Python→C++自动翻译等操作一并放出,直接给复现开了绿灯。
三步后训练,让模型“听得懂人话”
- 监督微调(SFT):1800万条多轮对话、竞赛题、终端操作记录,推理开关、预算控制、工具集成一次学全。
- 多环境强化学习(RLVR):数学、代码、指令遵循、长文QA等10个任务同步训练,互相不拉胯,200步后全面反超SFT。
- 人类反馈强化(RLHF):自研生成式奖励模型GenRM,16选1环形对比,长度惩罚+简洁奖励让回答短30%却不掉质量。
英伟达就用一篇报告、一行链接,把“小参数、高速度、长文本、强推理”的新标杆立了起来。接下来,就看开发者们怎么用它把成本打下来,把体验提上去了。
项目地址:https://huggingface.co/papers/2512.20848
 豫公网安备41010702003375号
豫公网安备41010702003375号