
Resemble AI推出Chatterbox Turbo,主打低延迟与真实表达
![]() 工具推荐
1766992377更新
工具推荐
1766992377更新
![]() 0
0
导读:完全开源、首音延迟低于150毫秒、仅需5秒音频即可复刻声音。Resemble AI 最新推出的 Chatterbox Turbo,正在把实时语音交互的门槛拉得更低。
语音 AI 这两年进步很快,但真正能“用得顺”的产品并不多,要么延迟高、要么算力吃紧,要么效果还停留在“像机器人念稿”的阶段。 Resemble AI 这次给出的解法,就是刚刚开源的 Chatterbox Turbo。
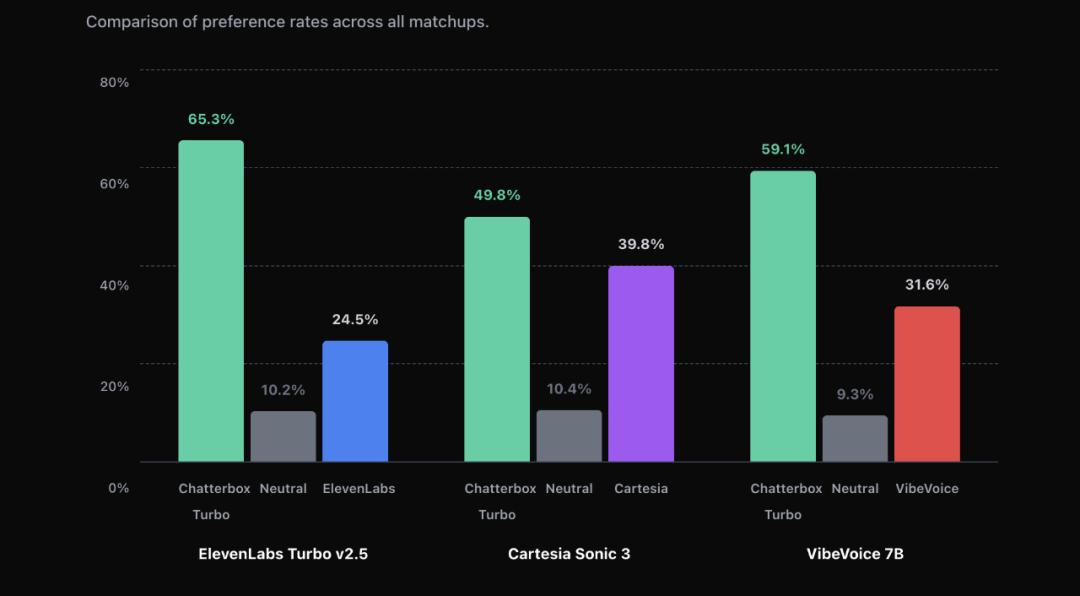
Chatterbox Turbo 从一开始就瞄准“低延迟语音交互”这个场景。官方给出的数据是,首音延迟低于150毫秒,基本贴近真人对话的响应速度。它不只是能“念出来”,而是真正可以用于实时语音助手、语音代理等场景。
在模型结构上,Turbo 采用约3.5亿参数的精简架构,对算力和显存的要求明显降低。更关键的一步是,开发团队对原本效率瓶颈明显的“语音 token 到 mel 解码器”进行了蒸馏优化,生成步骤从10步压缩到1步,同时保持音质不明显下降,这也是它能跑得更快的重要原因。
真实感,是 Chatterbox Turbo 另一条主线。
模型原生支持副语言标签(Paralinguistic Tags),比如 [laugh]、[cough]、[chuckle] 等。开发者可以直接在文本中标注,让合成语音出现自然的笑声、停顿和情绪变化,而不是一条从头到尾“平直输出”的声音。
在声音复刻上,Chatterbox Turbo 只需要约5秒参考音频即可完成克隆,无需额外训练。这一点对内容创作者、交互式应用和快速原型开发尤其友好。
Chatterbox Turbo 是100%开源,并采用 MIT 许可证,代码、模型权重、示例全部开放,既可以本地部署,也方便二次开发。 同时,Resemble AI 也保留了商业化路径:如果对规模化部署或更高稳定性有需求,可以使用其官方 TTS 服务,主打亚200毫秒级延迟,适合生产环境。
在模型体系上,Chatterbox 也并不只有 Turbo 一个版本:
- Chatterbox Turbo:主打低延迟与实时语音代理
- Chatterbox Multilingual:支持23种以上语言,适合全球化应用
- Chatterbox 标准版:强调可控性与创作自由度
所有生成的音频,还内置了不可感知的神经水印机制,在不影响听感的前提下,用于标识音频来源,提升可追溯性。
整体来看,Chatterbox Turbo 并不是“参数更大、指标更高”的那一类发布,而是一次非常明确的工程取向选择:更低延迟、更低门槛、更贴近真实对话的语音体验。
参考资料:https://github.com/resemble-ai/chatterbox
 豫公网安备41010702003375号
豫公网安备41010702003375号