
AI推理成主战场,英伟达下一代费曼GPU或引入Groq推理单元
![]() 前沿资讯
1766996658更新
前沿资讯
1766996658更新
![]() 0
0
导读:英伟达正评估,在下一代“费曼(Feynman)”GPU中,通过先进封装技术,引入来自格罗克(Groq)的LPU推理单元。
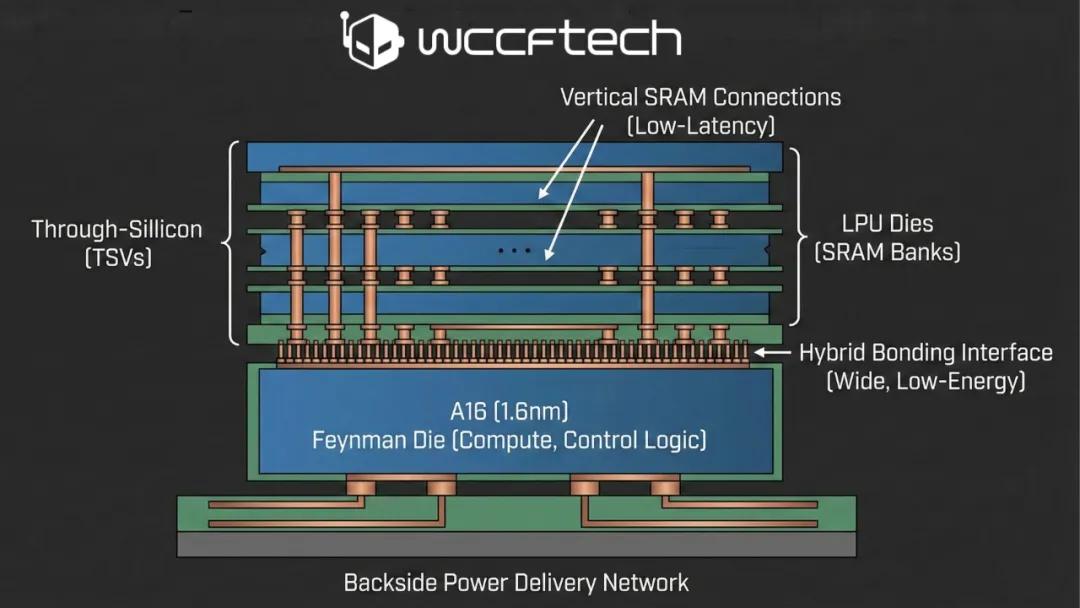
根据多位芯片领域人士的分析,英伟达可能最早在2028年前后,在“费曼(Feynman)”GPU中引入格罗克(Groq)的LPU(Language Processing Unit,语言处理单元)。这些LPU不会与GPU计算核心融为一体,而是以独立芯片的形式进行3D堆叠。

从现有情况来看,英伟达并不打算把大规模SRAM直接做进GPU主计算芯片。原因主要是:SRAM这种存储单元,在工艺升级后带来的体积和成本收益并不明显,如果强行放在先进制程节点上,不仅浪费高端硅资源,还会大幅推高单位面积成本。
相比之下,将LPU作为独立芯片,与GPU计算核心进行3D堆叠,是更可控、也更灵活的选择。
这种方式,预计会采用台积电(TSMC)的SoIC混合键合(Hybrid Bonding)技术。主计算芯片负责张量计算、控制逻辑等核心功能,而LPU芯片则主要承载大容量SRAM,用于推理阶段的高吞吐数据访问。
在具体实现上,费曼GPU的主芯片可能会使用A16(1.6nm)级别制程,并引入背面供电技术。这样一来,芯片正面可以为SRAM与LPU提供更高密度的垂直互连通道。
这种混合键合方式能显著降低每比特能耗,并缩短推理解码路径的延迟。对以推理为核心负载的数据中心来说,这是一个非常现实的性能红利。
不过,这条路线也会有一定的“代价”。 首先是散热与热密度问题。在高算力GPU之上再叠加LPU芯片,本身就会让热设计窗口更加紧张。而LPU强调持续吞吐,也可能在某些负载下形成新的瓶颈。
执行模型本身还有更复杂的挑战。LPU强调固定执行顺序和确定性,这与GPU长期强调的灵活调度机制存在天然冲突。在硬件层面解决之后,软件层面的适配压力会进一步放大。
尤其是在CUDA生态中,LPU式执行需要更明确的内存布局,而CUDA内核设计长期依赖硬件抽象。如何在不破坏现有开发体验的前提下,引入更“刚性”的推理执行路径,将是英伟达工程团队必须正面解决的问题。
如果英伟达希望在AI推理市场建立长期壁垒,引入LPU并重构GPU内部结构,可能是绕不开的一步。这不仅是一次封装或制程升级,更是一次围绕“推理优先”的体系级选择。
接下来几年,费曼GPU是否真的会迎来LPU堆叠方案,仍有变数。但可以确定的是,推理,正在成为下一代GPU竞争的主战场。
参考资料:https://wccftech.com/nvidia-feynman-gpus-could-see-the-inclusion-of-groq-lpu-units-by-2028/
 豫公网安备41010702003375号
豫公网安备41010702003375号