
"拼命奔跑才能留在原地":数字红皇后重现AI进化的奇迹时刻
![]() 前沿资讯
1768207610更新
前沿资讯
1768207610更新
![]() 0
0
【导读】在人工智能领域,如何让AI系统在动态对抗环境中持续进化一直是核心难题。日前,东京知名AI研究实验室Sakana AI发布了一项名为"Digital Red Queen(数字红皇后,DRQ)"的研究,为理解AI系统的 adversarial 动态提供了全新视角。
"在这里,要保持原地不动,就得用尽全力奔跑。"——红皇后对爱丽丝说,刘易斯·卡罗尔《镜中奇遇》
这句名言揭示了自然界"永不停歇进化竞赛"的规律。在生物学中,红皇后假说表明,生物必须不断进化才能维持相对竞争优势。随着大语言模型日益融入现实世界,当AI系统相互作用时,是否会展现类似动态?为探索这一问题,Sakana AI的研究团队设计了Digital Red Queen(DRQ),利用Core War游戏作为沙盒,为我们揭开了AI对抗进化的神秘面纱。
Core War诞生于1984年,是独特的竞争性编程游戏。玩家编写"战士",使用类汇编语言Redcode,在共享内存空间中进行生存竞争。每个战士试图成为最后存活者,通过让对手崩溃实现目标。
DRQ的核心思想是:通过多轮进化优化,让新战士不断挑战所有先前战士。每轮使用LLM生成和变异战士,利用MAP-Elites算法保持多样性,新战士需在对抗所有历史战士中证明价值。
研究揭示了几个重要特性。
如果只让AI训练一轮来对付某个特定对手,它确实能变得很厉害,但这种"厉害"是狭隘的。具体来说,单轮优化产生的战士群体作战能力很强,集体能打败绝大多数人类设计的对手,但单独拎出来一个,很多都只能对付不到三成的敌人。
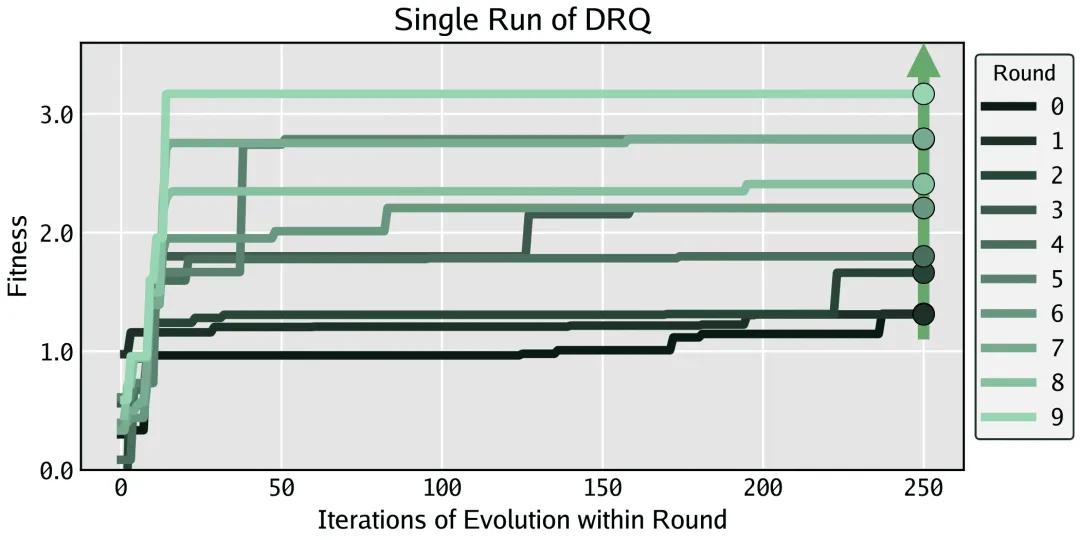
但故事在多轮训练后发生了转变。完整的DRQ训练让战士经历了多轮"淘汰赛",每一轮都要面对之前所有对手的挑战。研究人员观察到一个惊人的现象:随着训练轮次增加,这些战士变得越来越"全面",能够应对更多样化的敌人。
更神奇的是,不同批次独立训练产生的战士,虽然在行为表现上越来越像,但在源代码层面却保持了各自的特点。这种"殊途同归"的现象,就像自然界中不同物种独立进化:解决问题的路径不同,但最终达到了相似的最优解。
DRQ研究意义远超Core War游戏本身,代表AI研究从静态问题向开放环境转变的重要一步。
随着AI大模型在金融、医疗、政务等关键领域的深度渗透,大模型安全性已超出传统网络安全范畴。DRQ和Core War的结合,为理解这些 adversarial 动态提供了一个安全而富有洞察力的起点。
正如研究所指出的,在动态变化环境中,通用鲁棒的策略可能从持续自博弈中自然涌现,这为未来AI系统的设计和安全加固提供了重要的理论指导。
参考资料:https://pub.sakana.ai/drq/
 豫公网安备41010702003375号
豫公网安备41010702003375号