
百川智能发布最新医疗大模型:Baichuan-M3-235B
![]() 前沿资讯
1768387945更新
前沿资讯
1768387945更新
![]() 0
0
【导读】长期以来,"建议尽快就医"这类模糊回答让用户深感困惑,而且,一旦给出错误医疗建议,后果不堪设想。百川智能最新发布的Baichuan-M3-235B模型,通过两项核心技术突破实现了幻觉率低于GPT-5.2,并在权威评测中超越OpenAI最新模型。
在医疗AI领域,"建议尽快就医"这类模糊回答已成为行业痛点。由于大模型在医疗场景下最怕的就是"幻觉",一旦胡说八道后果不堪设想,因此各大厂商只能采取保守输出策略。现在,这一局面正在被打破。
百川智能开源发布了新一代医疗增强模型:Baichuan-M3-235B,通过技术手段深度优化了幻觉问题,为医疗AI的可靠性树立了新的行业标杆。

Baichuan-M3-235B的技术创新聚焦于两个核心方向:SPAR分段管道强化学习与Fact-Aware RL事实感知强化学习。
SPAR分段管道强化学习是百川智能针对医疗临床决策特点提出的创新训练方法。该技术将复杂的临床流程拆解为病史采集、鉴别诊断、实验室检查、最终诊断四个独立阶段,每个阶段都设置了针对性的奖励机制。这种分段式训练方法使模型能够学会完整的临床决策逻辑,而不仅仅局限于回答单个问题,从而大幅提升了模型在真实医疗场景中的实用价值。
Fact-Aware RL事实感知强化学习则是解决医疗幻觉问题的另一关键技术。百川智能在模型训练过程中直接集成了在线幻觉检测模块,能够实时对照权威医学证据库验证模型输出。据官方数据显示,即使不借助任何外部工具,Baichuan-M3-235B的幻觉率也比GPT-5.2更低。
在OpenAI发布的权威医疗评测基准HealthBench上,Baichuan-M3-235B展现出强劲实力。HealthBench由来自60个国家的262名执业医师共同构建,包含5000个高保真多轮临床对话场景,是目前医疗AI领域最具权威性的评测标准之一。
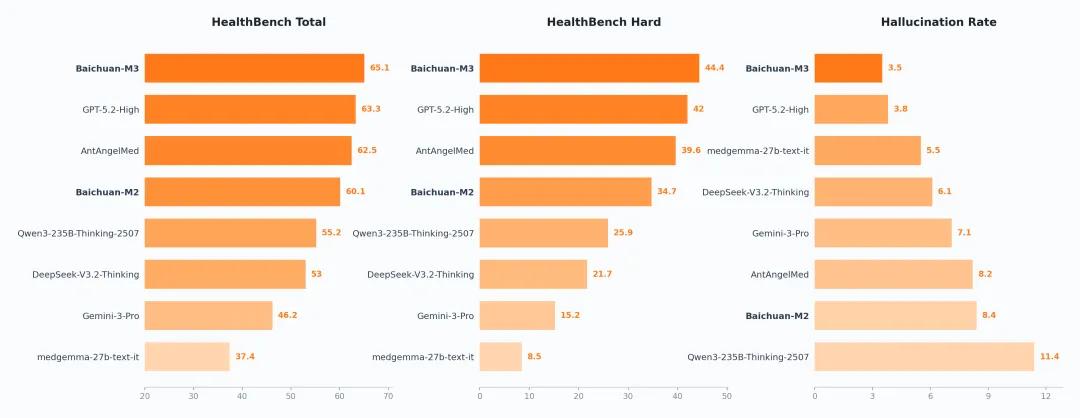
具体来看,Baichuan-M3-235B在HealthBench-Hard评测中取得44.4分的成绩,比上一代M2模型整整提升了28个百分点,并成功超越OpenAI最新发布的GPT-5.2模型。
在SCAN-bench端到端临床决策评测中,Baichuan-M3-235B更是展现出全面领先的优势。SCAN-bench模拟了从患者问诊到最终诊断的完整临床工作流程,通过三个核心维度评估模型的高保真临床问诊能力。Baichuan-M3-235B成为唯一一个在临床问诊、实验室检测、最终诊断三个维度均排名第一的模型,其中临床问诊能力领先第二名12.4分,优势显著。
百川智能CTO表示:"与此前主要聚焦于静态问答或表面角色扮演的医疗AI不同,Baichuan-M3-235B的训练目标是显式建模临床决策过程,旨在提升医疗AI在真实医疗实践中的可用性和可靠性。"
项目地址:https://huggingface.co/baichuan-inc/Baichuan-M3-235B
 豫公网安备41010702003375号
豫公网安备41010702003375号