
阶跃星辰开源Step 3.5 Flash:11B撬动196B,性能甚至还能超越闭源顶级模型?
![]() 前沿资讯
1770028437更新
前沿资讯
1770028437更新
![]() 0
0
导读:阶跃星辰最新开源 Step 3.5 Flash,这个仅有 196B 参数的稀疏 MoE 模型,每次推理仅激活 11B 参数,却能在多项关键基准测试中超越甚至持平 DeepSeek V3.2、Kimi K2、GLM-4.7 等顶级闭源模型。而且,消费级硬件即可本地部署。
阶跃星辰(StepFun)宣布推出 Step 3.5 Flash,这是一款基于稀疏混合专家(MoE)架构的开源基础模型,旨在以 更低的计算成本实现前沿级别的推理与Agent能力。
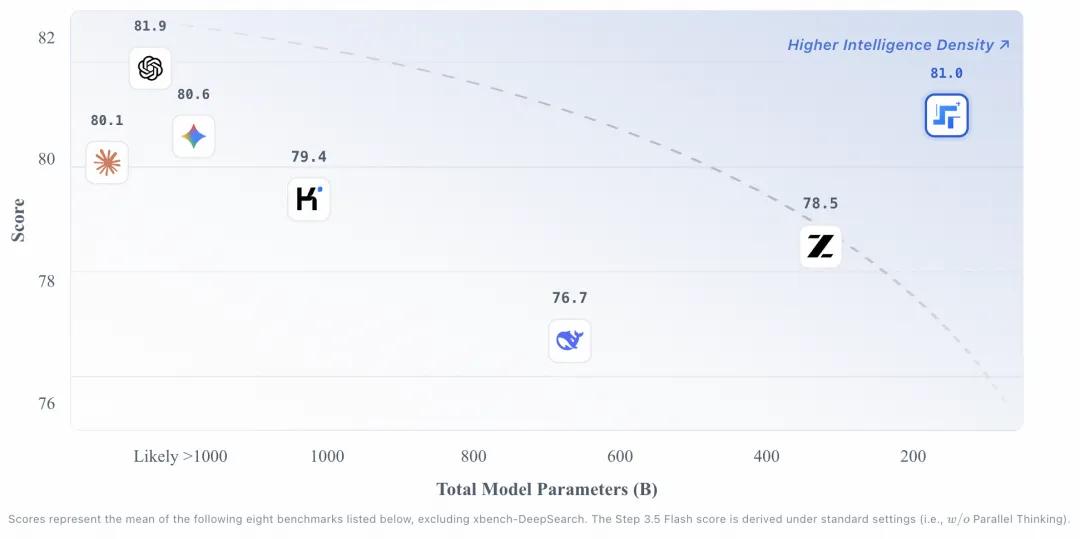
Step 3.5 Flash 的主要创新在于其 "智能密度"(Intelligence Density) 设计理念。该模型采用稀疏混合专家架构,总参数量达到 196B,但 每次仅激活约 11B 参数进行推理。这种设计可以让模型在保持大参数"记忆容量"的同时,运行效率与 11B 级别的 dense 模型相当。
从架构细节来看,Step 3.5 Flash 包含 45 层 Transformer(隐藏维度 4096),配备 256K 上下文窗口,词表规模达到 128896 tokens。在 MoE 路由层面,每层包含 288 个可路由专家 + 1 个共享专家,系统 每次仅选取 Top-8 专家进行激活,实现了真正意义上的稀疏计算。
速度是 Agent 应用的核心竞争力。Step 3.5 Flash 搭载了 MTP-3(三路多Token预测) 技术,通过专用的滑动窗口注意力机制和前馈网络模块,单次前向传播可同时预测 4 个 token。这使得模型在典型使用场景下达到 100-300 tok/s 的生成吞吐量,单流编码任务峰值可达 350 tok/s。
作为对比,同等参数级别的竞品模型中,DeepSeek V3.2 约为 33 tok/s(MTP-1),Kimi K2 Thinking 约为 33 tok/s(无 MTP)。在 128K 上下文、Hopper GPU 环境下,Step 3.5 Flash 的解码成本仅为 1.0x,而 DeepSeek V3.2 为 6.0x,Kimi K2 为 18.9x,成本优势达到 6-19 倍。
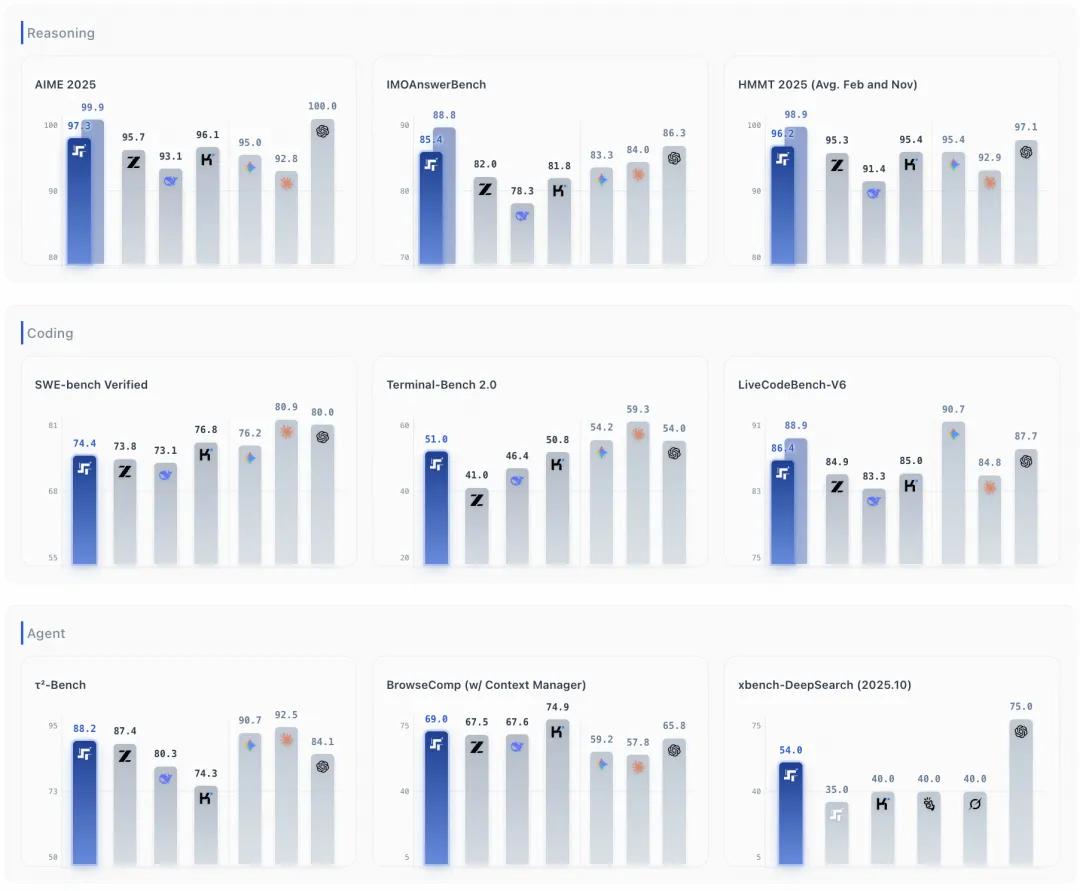
根据官方公布的基准测试数据,Step 3.5 Flash 在 推理、编码、Agent 能力 三大维度均展现出强劲竞争力:
Agent 能力方面,Step 3.5 Flash 在 τ²-Bench 达到 88.2% (DeepSeek V3.2 为 80.3%,Kimi K2 为 74.3%),BrowseComp 达到 51.6% ,BrowseComp-ZH 达到 66.9% ,GAIA(无文件)达到 84.5% ,xbench-DeepSearch(2025.05)达到 83.7% 。
推理能力方面,Step 3.5 Flash 在 AIME 2025 达到 97.3% ,HMMT 2025(2月)达到 98.4% ,HMMT 2025(11月)达到 94.0% ,IMOAnswerBench 达到 85.4% ,全面超越 DeepSeek V3.2 和 Kimi K2。
编码能力方面,LiveCodeBench-V6 达到 86.4% ,SWE-bench Verified 达到 74.4% ,Terminal-Bench 2.0 达到 51.0% 。其中,SWE-bench Verified 和 Terminal-Bench 2.0 是衡量模型处理复杂、长周期编码任务能力的关键指标,Step 3.5 Flash 的表现已经接近甚至超越部分顶级闭源模型。
为了在长上下文场景下保持高效推理,Step 3.5 Flash 采用 3:1 滑动窗口注意力(SWA)比例,即每 1 层全注意力层搭配 3 层滑动窗口注意力层。这一混合架构确保模型在处理 大规模数据集或长代码库 时保持稳定性能,同时 显著降低了标准长上下文模型的计算开销。
Step 3.5 Flash 的另一大亮点是其 出色的本地部署友好性。经过优化后,模型可在以下消费级硬件上安全运行:
- Mac Studio M4 Max(统一内存架构)
- NVIDIA DGX Spark
- AMD Ryzen AI Max+ 395
通过 llama.cpp 部署时,模型 GGUF 权重(int4 量化)体积约为 111.5GB,运行时开销约 7GB,最低 VRAM 要求为 120GB,推荐 128GB 统一内存。
Step 3.5 Flash 提供 云端 API 和 本地部署 两种使用方式:
云端 API 支持 OpenRouter 和 StepFun 官方平台。其中,OpenRouter 目前提供 免费试用额度,开发者可通过标准 OpenAI SDK 快速接入。
本地部署 方面,Step 3.5 Flash 已完成与主流推理框架的深度适配,支持:
- vLLM(推荐使用 nightly 版本)
- SGLang
- Hugging Face Transformers
- llama.cpp
此外,Step 3.5 Flash 已在 Claude Code 和 Codex 等主流 Agent 开发环境中完成集成验证,开发者可将模型配置为默认推理引擎。
稀疏 MoE 架构 + MTP-3 多Token预测的组合拳,使得 Step 3.5 Flash 模型在保持高性能的同时,将推理成本压缩至竞品的 1/6 至 1/19。对于追求 低成本、高效率 Agent 部署的开发者而言,这无疑是一个值得关注的新选择。
参考资料: https://mp.weixin.qq.com/s/XYH-5lZ3z3bw8VOEemyeSQ
 豫公网安备41010702003375号
豫公网安备41010702003375号