
对标Cursor,阿里发布Qwen-Coder-Qoder:首个大规模强化学习驱动的编程Agent模型
![]() 前沿资讯
1770110850更新
前沿资讯
1770110850更新
![]() 0
0
导读:通义千问团队正式发布了 Qwen-Coder-Qoder,这是一款专门为 Qoder 编程助手定制的强化学习模型,基于 Qwen-Coder 基座,在真实软件工程任务场景下进行了大规模强化学习训练。测评数据显示,Qwen-Coder-Qoder 的任务解决率超越了 Cursor Composer-1,尤其在 Windows 系统下的终端命令准确率方面领先幅度达到 50%。
市面上大多数 AI 编程模型的目标很简单:把问题解决就行。但真正的软件工程需要:遵循项目编码规范,理解整个代码库的上下文结构,还要考虑修改是否会影响其他模块。这些能力,通用模型往往不具备。
Qwen-Coder-Qoder 正是要解决这个问题。该模型基于 Qwen-Coder 基座,紧贴 Qoder Agent 的框架、工具与真实使用场景,进行了大规模强化学习训练。
模型展现出四个核心能力:严格遵循软件工程规范,可以保持与项目一致的代码风格;理解完整项目上下文,通过学习代码图谱、项目记忆、Repo Wiki 等,从全局视角理解代码仓库;高效的并行处理能力,能够并行执行代码检索、任务规划、多位置代码修改等操作;坚韧的问题解决能力,面对困难时持续尝试,直至问题解决。
该模式使用数据显示,线上代码留存率提升了 3.85%,工具异常率下降 61.5%,Token 消耗下降 14.5%,整体已接近世界顶级模型水平。
技术探秘:三个核心要素支撑模型训练
1、真实的 Qoder Agent 沙盒环境。 团队让模型充分学习使用 Qoder 的 Knowledge、Memory、Tools/MCP、Context 等解决真实编程任务。依靠虚拟化容器技术,可快速拉起和销毁数万级别的容器,满足大规模强化学习训练需求。
2、真实的软件工程最佳实践奖励信号。 团队启用了单元测试验证、命令行验证、多维任务验证等多种正确性验证方式,同时对编码风格、复用性、耦合度等过程指标进行约束。Reward Hacking 是主要挑战,团队专门构建了 "Rewarder - Attacker" 对抗式审查机制来解决这一问题。
3、大规模高效的强化学习训练框架。 Qwen-Coder-Qoder 使用 ROLL 训练框架,通过异步调度、KV cache 复用、跨版本样本生成、training 与 rollout 异步并行等优化,实际获得 10× 以上吞吐提升,显著缩短训练周期。
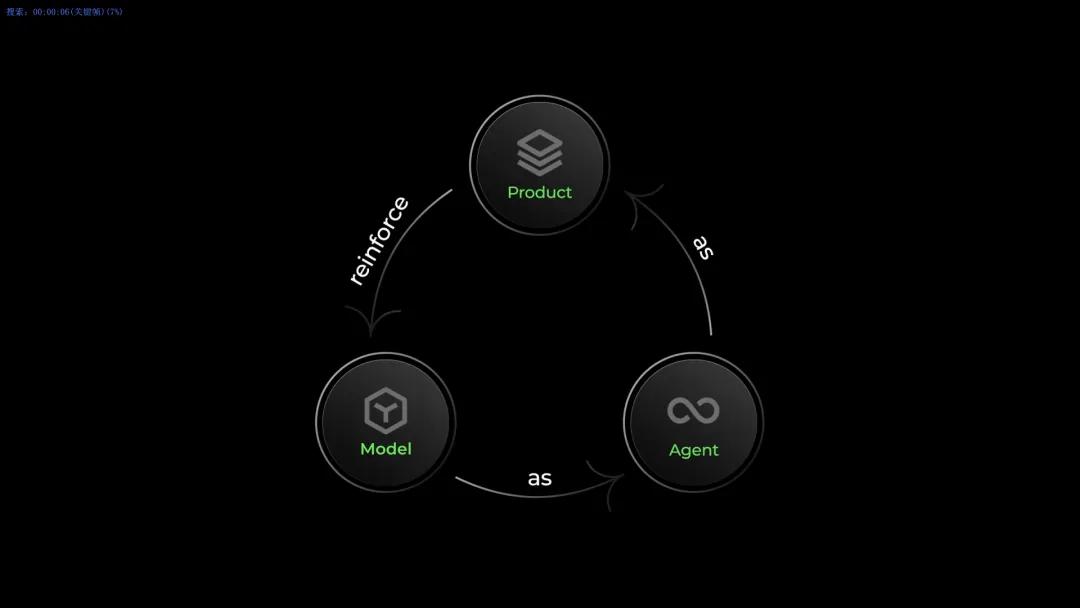
阿里云构建了一个"模型即 Agent,Agent 即产品,产品增强模型"的智能进化体系。
模型是基础,直接驱动 Agent 执行任务;Agent 是核心,一切功能都围绕它展开;产品触达用户,收集真实的使用数据和反馈,这些数据反过来成为增强模型训练的重要信号。
这让模型从真实的产品环境中学习,在真实的软件开发任务中成长,用真实的软件工程最佳案例作为奖励信号。
与竞争对手相比,Qwen-Coder-Qoder 的差异化也在于其"模型-智能体-产品"三位一体的智能进化体系。它将模型训练、产品迭代、用户反馈有机整合,形成了一个持续进化的生态系统。
从实际效果来看,作为一个初版模型,Qwen-Coder-Qoder 已经展示了巨大的提升空间。随着训练的持续迭代和技术的不断成熟,其表现有望进一步提升。
参考资料:https://qoder.com/blog/qwen-coder-qoder
 豫公网安备41010702003375号
豫公网安备41010702003375号