
可灵3.0 Omni:当一致性控制遇到原生音频,每个人离导演只差一个Prompt
![]() 工具推荐
1770277827更新
工具推荐
1770277827更新
![]() 0
0
导读:快手旗下的 Kling 最新发布了全新升级的 3.0 版本,单次生成时长从 10 秒延长到15 秒、原生音频支持、角色语音绑定、分镜头精准控制……如果你之前对 AI 视频工具的印象还停留在"玩具"阶段,这次可能需要重新审视了。
Kling 3.0 系列包含两个版本:VIDEO 3.0 和 VIDEO 3.0 Omni。前者是 VIDEO 2.6 的升级版,后者则是 VIDEO O1 的进阶版本。两者共享同一套底层训练框架,但在输入输出能力上各有侧重。
VIDEO 3.0 Omni 是本次更新的核心亮点,实现了真正的"All-in-One"多模态输入输出能力。
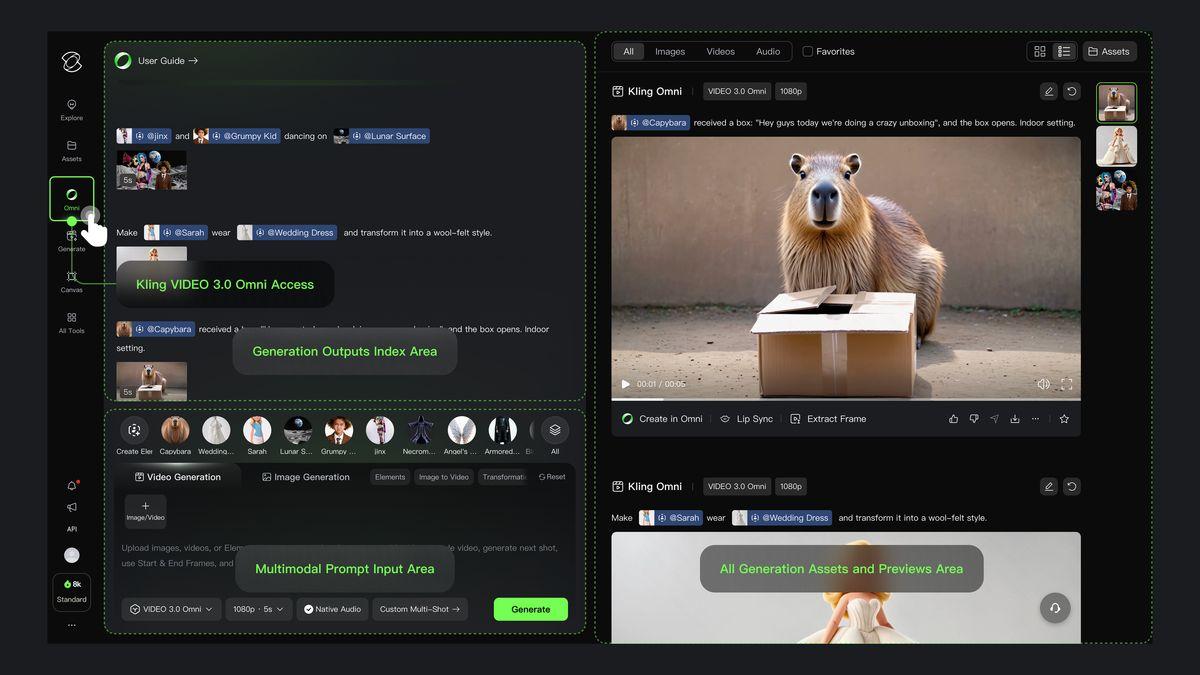
最直观的变化是生成时长的提升,从之前的 10 秒直接扩展到 15 秒,你可以用一次生成完成更完整的叙事表达,镜头切换更从容,节奏把控更细腻。
原生音频支持的加入是另一个关键突破。 以往的 AI 视频工具大多只能生成画面,声音需要后期配音或对口型,流程繁琐且效果参差。Kling 3.0 Omni 现在支持直接生成带音频的视频片段,包括多角色对话、旁白解说等多种场景。虽然目前原生音频模式只支持无视频输入的生成,但官方已经预告了视频输入场景即将支持。
AI 视频生成领域还有一个长期痛点:角色在多镜头中样貌不稳定。同一个角色,上一个镜头是黑发,下一个镜头可能变成了棕发,背景里的关键道具也会在不同帧中"变脸"。这些问题严重限制了 AI 视频在实际创作中的应用。
本次,Kling 3.0 Omni 带来了 Elements 3.0,通过全新的"全合一参考 3.0"机制,可以将上传的图片、视频、元素和文字统一视为"提示词",模型在底层语义层面完成理解和融合。
当你上传一段角色的多角度视频或图片后,模型会锁定该角色的视觉特征,无论镜头如何运动、光线如何变化,角色的脸型、服饰、表情细节都能保持高度一致。而且,这种一致性在复杂群像场景中依然有效,每个角色、每个道具都能被独立锁定,各司其职,互不干扰。
为角色绑定专属声音。在创建角色元素时,你可以上传一段 3-8 秒的视频,模型会自动提取角色的外观特征和原始声音,或者上传一段清晰的语音录音,模型会学习这段声音的音色和韵律特征。绑定完成后,该角色的声音会被"固化",在后续任何视频生成中无需重复指定,模型会自动调用。
现在,你可以创建一个"虚拟演员",他的脸是他的,他的声线也是他的,无论你让他出现在什么场景、说什么台词,他都保持高度一致。官方将这种能力称为带声音的角色资产。对于需要持续产出系列内容、塑造统一角色形象的创作者而言,这个功能极具实用价值。
Kling 3.0 目前提供 1080p 和 720p 两种分辨率选项。生成消耗的积分取决于是否开启原生音频、是否有视频输入以及最终产出的视频时长。
| 模式 | 分辨率 | 原生音频开启 | 原生音频关闭 |
|---|---|---|---|
| 无视频输入 | 1080p | 12 积分/秒 | 8 积分/秒 |
| 无视频输入 | 720p | 9 积分/秒 | 6 积分/秒 |
| 有视频输入 | 1080p | 暂不支持 | 16 积分/秒 |
| 有视频输入 | 720p | 暂不支持 | 12 积分/秒 |
Ultra 订阅用户目前已获得专属抢先体验权限,普通用户可以关注官方渠道的后续开放节奏。
从 Sora 到 Runway 再到 Kling,AI 视频生成正在从"能生成"走向"能控制"。15 秒的时长、原生音频、多模态输入、角色声音绑定,这些能力叠加在一起,已经足以支撑一些轻量级的短视频内容生产。
参考资料:https://x.com/Kling_ai/status/2019064918960668819
 豫公网安备41010702003375号
豫公网安备41010702003375号