
OpenAI发布GPT-5.3-Codex:史上最强编码Agent模型,速度提升25%,还能自我训练
![]() 工具推荐
1770359666更新
工具推荐
1770359666更新
![]() 24
24
导读:OpenAI 正式发布 GPT-5.3-Codex,这是目前最强大的代理编码模型。新模型在 SWE-Bench Pro、Terminal-Bench 2.0、OSWorld 等关键基准测试中均创下行业新高,整体性能较上一代提升约 25%。另外,GPT-5.3-Codex 已被用于自我训练和部署,实现了模型开发的闭环。
OpenAI 正式发布全新一代代理编码模型 GPT-5.3-Codex。该模型不仅在编码性能上实现了显著突破,更标志着 AI 从「辅助编程」向「自主开发」的关键跨越。新模型的推理速度比 GPT-5.2-Codex 快 25% ,能够在更短的时间内完成更复杂的开发任务。
GPT-5.3-Codex 的核心创新在于其全栈代理能力。
与前代产品相比,新模型不再局限于代码编写和审查,而是扩展到能够完成开发者在计算机上进行的几乎所有操作。更重要的是,用户可以在模型工作过程中随时介入和引导,而不会丢失上下文信息,就像与一位真正的同事协作一样自然流畅。
基准测试方面,在 SWE-Bench Pro 测试中,该模型达到了 56.8% 的准确率,这是目前该测试的最高分。SWE-Bench Pro 是一个严格评估真实世界软件工程能力的基准,相比仅测试 Python 的 SWE-Bench Verified,它涵盖了四种编程语言,更具抗污染性、挑战性、多样性和行业相关性。
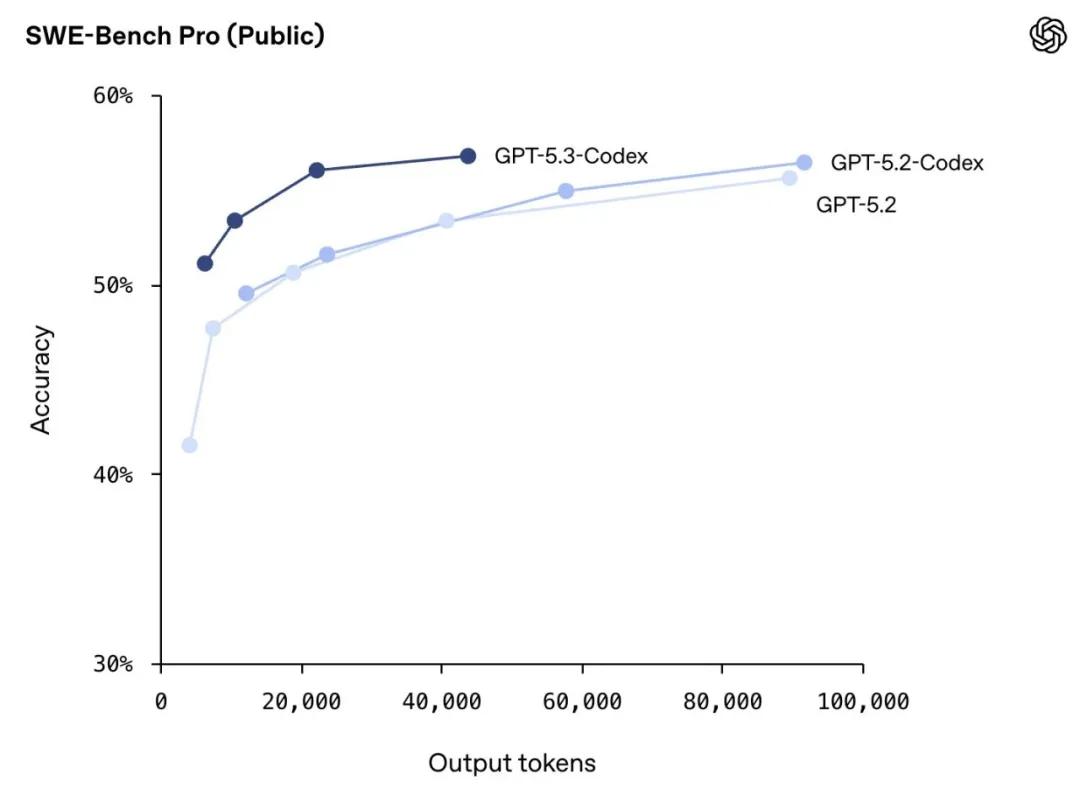
在 Terminal-Bench 2.0 测试中,GPT-5.3-Codex 取得了 77.3% 的准确率,显著超越了 GPT-5.2-Codex 的 64.0%。在 OSWorld-Verified 评测中,模型的准确率达到 64.7% (人类水平约为 72%)。
| 基准测试 | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 |
|---|---|---|---|
| SWE-Bench Pro | 56.8% | 56.4% | 55.6% |
| Terminal-Bench 2.0 | 77.3% | 64.0% | 62.2% |
| OSWorld-Verified | 64.7% | 38.2% | 37.9% |
| GDPval(胜率或平局) | 70.9% | — | 70.9% |
| 网络安全 CTF 挑战 | 77.6% | 67.4% | 67.7% |
| SWE-Lancer IC Diamond | 81.4% | 76.0% | 74.6% |
GPT-5.3-Codex 的另一项突破性应用是自我迭代。
据 OpenAI 透露,这是第一个在创建自身过程中发挥关键作用的模型。Codex 团队使用早期版本调试训练过程、管理部署、诊断测试结果和评估,结果,他们对 Codex 能够大幅加速自身开发的能力感到震惊。这种「自我训练」的能力标志着 AI 开发进入了新的阶段,模型不再只是被动的工具,而是能够主动参与自身优化的智能系统。
在可用性方面,GPT-5.3-Codex 已向所有付费 ChatGPT 计划用户开放,用户可以在 Codex 应用程序、CLI、IDE 扩展和网页中使用该模型。OpenAI 表示正在努力尽快安全地启用 API 访问。
随着 GPT-5.3-Codex 的发布,Codex 正从「编写代码」扩展到「使用代码作为工具来操作计算机并端到端完成任务」。通过推进编码代理的能力边界,OpenAI 也在解锁更广泛的知识工作类别。这种能力的扩展不仅改变了谁可以构建,也改变了用 Codex 能够实现的可能性。
参考资料:https://openai.com/index/introducing-gpt-5-3-codex
 豫公网安备41010702003375号
豫公网安备41010702003375号