
Anthropic旗舰模型Claude Opus 4.6发布,1M上下文时代到来,能否成为开发者新标配?
![]() 工具推荐
1770365589更新
工具推荐
1770365589更新
![]() 0
0
导读:Anthropic 发布了全新旗舰模型 Claude Opus 4.6,在编程、推理和长上下文处理方面实现了显著突破。该模型在 Terminal-Bench 2.0 和 Humanity's Last Exam 等权威基准测试中取得最高分,在经济价值知识工作评估 GDPval-AA 上领先 GPT-5.2 约 144 个 Elo 点。最值得关注的变化是 Opus 4.6 首次在 Opus 系列中开放 1M token 上下文窗口测试版,并引入了自适应思考、努力控制等全新开发者功能。
Anthropic 正式发布了全新旗舰模型 Claude Opus 4.6,该模型在编程能力、任务规划、代码审查和调试等方面均有显著提升,同时首次在 Opus 级别模型中开放了 1M token 上下文窗口测试版。
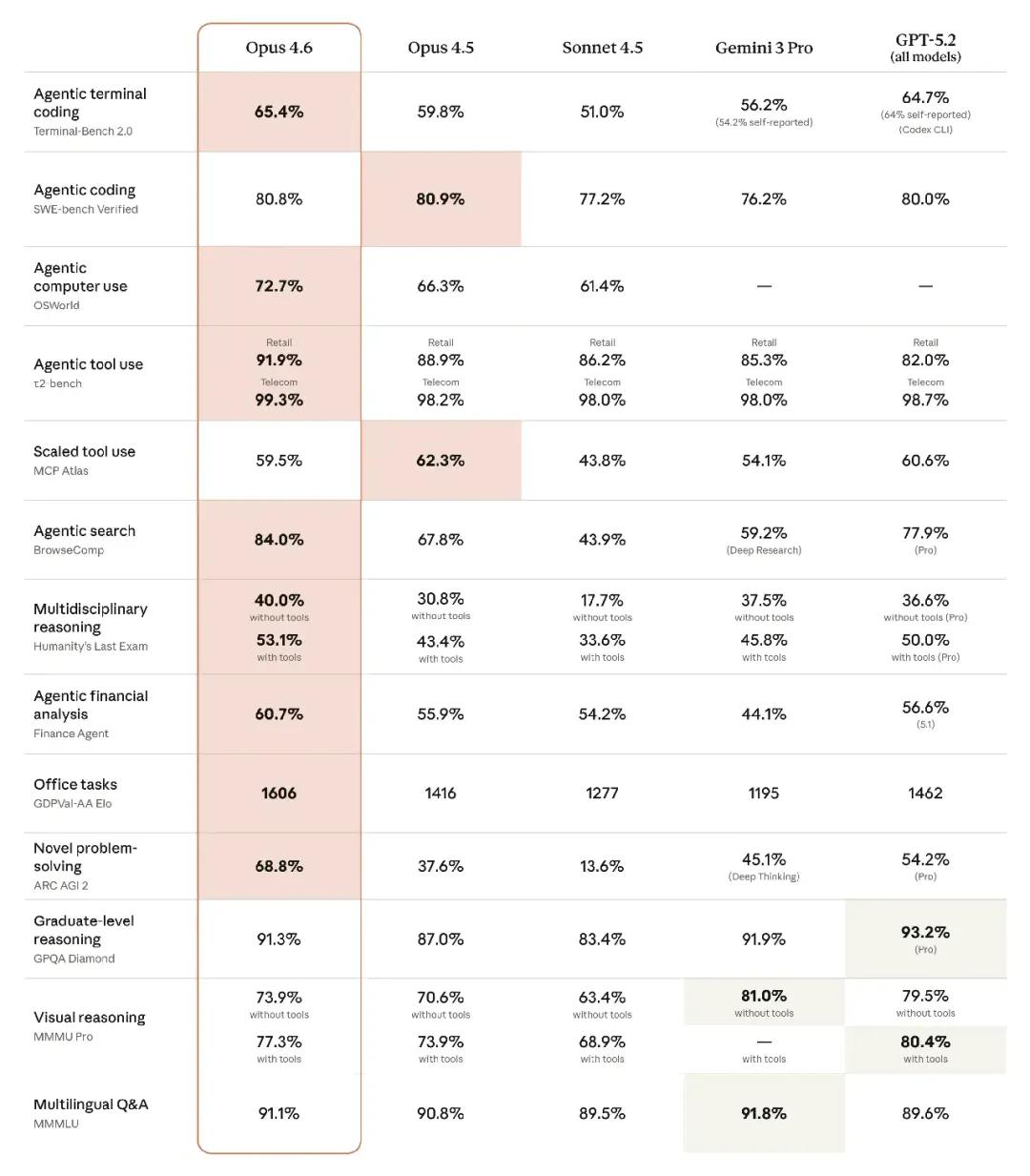
核心能力突破
Claude Opus 4.6 在多个关键领域实现了实质性升级。在编程能力方面,模型能够进行更谨慎的任务规划,在大型代码库中保持更稳定的自主运行,并具备更强的代码审查和自我调试能力,能够主动发现并修正自身错误。在实际工作场景中,Opus 4.6 可胜任财务分析、研究任务、文档处理、电子表格创建和演示文稿制作等多种日常工作。
基准测试表现方面:在代理编程评估 Terminal-Bench 2.0 中取得最高分,在复杂多学科推理测试 Humanity's Last Exam 中领先所有前沿模型。
更具实际意义的是,在评估经济价值知识工作能力的 GDPval-AA 基准测试中,Opus 4.6 领先 OpenAI 的 GPT-5.2 约 144 个 Elo 点,相较前一代 Opus 4.5 提升了 190 个 Elo 点。
长上下文处理是 Opus 4.6 的核心亮点之一。在needle-in-a-haystack 基准测试 MRCR v2 的 8-needle 1M 变体中,Opus 4.6 得分达到 76%,而前一代 Sonnet 4.5 仅能获得 18.5% 的分数。
新模型能够在百万 token 的超长上下文中准确检索信息,有效解决了长期困扰用户的"上下文衰减"问题。
开发者新功能
Anthropic 同时推出了一系列面向开发者的新功能。自适应思考功能让模型能够根据上下文判断何时需要深度推理,开发者可通过努力参数在 low、medium、high(默认)和 max 四个级别中选择。上下文压缩功能可自动总结和替换较早的对话内容,使模型能够执行更长任务而不会触及上下文限制。
在产品层面,Claude Code 引入了代理团队功能预览,允许开发者启动多个并行工作的代理组成团队,特别适合代码库审查等需要大量独立阅读的任务。此外,Claude in Excel 实现了重大升级,而 Claude in PowerPoint 也以研究预览形式推出,能够读取布局、字体和幻灯片母版以保持品牌一致性。
Claude Opus 4.6 已通过 claude.ai、API 及所有主流云平台开放使用。开发者可通过 Claude API 使用 claude-opus-4-6 端点,定价保持不变为每百万 token 5/25。1M token 上下文窗口的测试版对超过 200k token 的提示采用溢价定价,每百万输入/输出 token 为 10/37.50。
参考资料:https://www.anthropic.com/news/claude-opus-4-6
 豫公网安备41010702003375号
豫公网安备41010702003375号