
豆包2.0发布,推理成本降低约一个数量级:从“能说会道”到“能征惯战”
![]() 前沿资讯
1771064616更新
前沿资讯
1771064616更新
![]() 37
37
豆包大模型2.0系列正式发布。
如果只看技术参数,这只是一次常规的版本迭代,包括多模态能力提升、推理成本下降、长程任务执行能力增强。
但若仔细审视,会一个关键数据:推理成本降低了约一个数量级。它让Agent技术在真实业务场景中大规模落地,从一个技术可能性变成了一个经济可行性命题。
这不只是“更便宜”这么简单。在Agent技术的落地逻辑中,推理成本是一个决定性的约束条件。因为Agent执行一个复杂任务,需要反复调用模型进行多轮推理,消耗的Token量远大于单次问答。当成本下降一个数量级后,过去在经济学上不可行的Agent应用场景,突然变得有利可图了。
这就是为什么豆包2.0的发布不是一个简单的产品更新,而是一个经济层面的范式信号。
成本是进入门槛,能力是天花板。
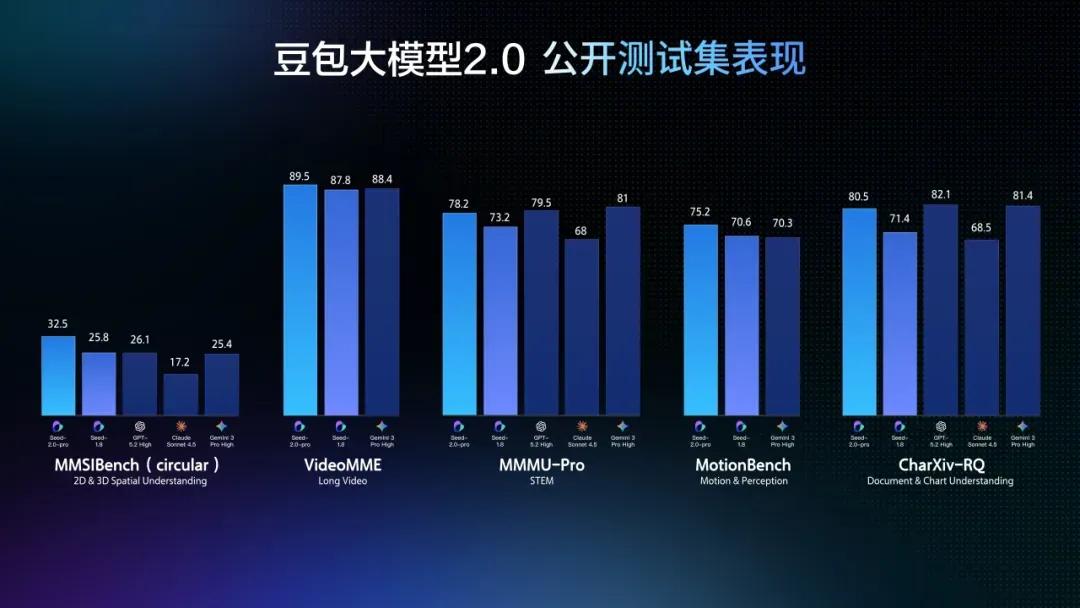
豆包2.0在多模态理解上的突破,同样不是一个温和的改进。在各类视觉理解任务上,豆包2.0 Pro在大多数相关基准测试中取得最高分,视觉推理、空间推理、长上下文理解能力均达到世界顶尖水平。
但更有判断价值的信息在于:豆包2.0在EgoTempo基准上超过了人类分数。这个基准测试的是对“变化、动作、节奏”这类时间序列信息的捕捉能力。AI在这项指标上超越人类,意味着它对物理世界动态的理解已经比普通人更稳定、更可靠。
这带来一个直接的技术后果:过去Agent只能处理静态信息,现在它可以理解和响应动态环境。在字节跳动展示的长视频理解能力中,豆包2.0能够完成实时视频流分析、环境感知、主动纠错与情感陪伴,实现从被动问答到主动指导的交互升级。
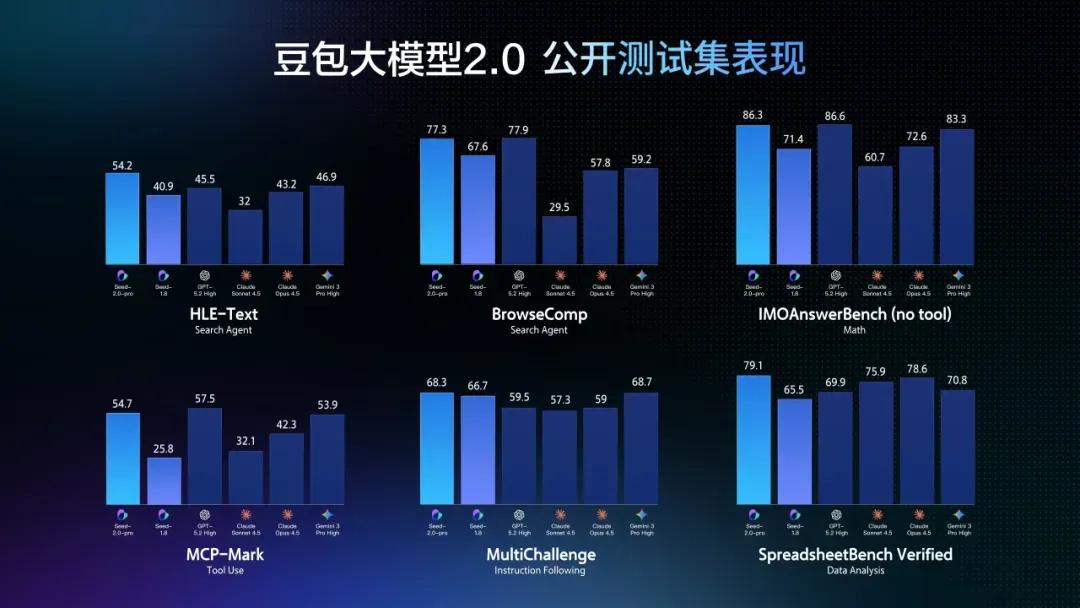
所有的能力提升,最终都要落实到“完成任务”这个维度上来检验。
豆包2.0 Pro在推理和Agent能力评测中表现强劲:在IMO、CMO数学奥赛和ICPC编程竞赛中获得金牌成绩,超越了Gemini-3 Pro在Putnam Bench上的表现。更关键的是,在HLE-text(被称为“人类的最后考试”)上,豆包2.0 Pro取得最高分54.2分。
分数当然重要,但更值得关注的是落地案例。字节跳动在飞书上构建的智能客服Agent,展示了一个具备完整任务执行能力的Agent应该是什么样子。这个Agent能够调用不同技能完成客户对话,当遇到无法解决的难题时,它会主动拉群求助真人同事,帮客户预约上门维修人员,并在维修后主动进行回访,同时推荐相关产品。
这个案例说明了一个事实:Agent已经具备了“替代人工完成完整业务流程”的能力。它不是简单地回答问题,而是在整个服务链条上代替人做决策、调用工具、跟进结果。当这种能力与成本下降叠加在一起,产生的化学反应是:过去只有大型科技公司才能负担的Agent应用,现在中小企业也可以部署了。
豆包大模型2.0系列的更新,是面向现实世界复杂任务的新起点。它预示着AI竞争正在进入一个新阶段:不再是参数和分数的比拼,而是实用性和成本控制的较量。这场较量的胜负,将由谁能更快地将AI能力转化为真实业务价值来决定。
参考资料:https://mp.weixin.qq.com/s/1dlAeBOu1FPkCabQ_UIMEA
 豫公网安备41010702003375号
豫公网安备41010702003375号