
京东开源JoyAI-LLM Flash:480亿参数,30亿激活,推理吞吐量提升1.7倍
![]() 工具推荐
1771147410更新
工具推荐
1771147410更新
![]() 1
1
京东开源发布JoyAI-LLM Flash,这是一款基于混合专家(MoE)架构的指令微调模型。从参数规模看,该模型总参数480亿,激活参数30亿,采用256专家设计,每个token激活8个专家,MLA注意力机制,支持128K上下文窗口。
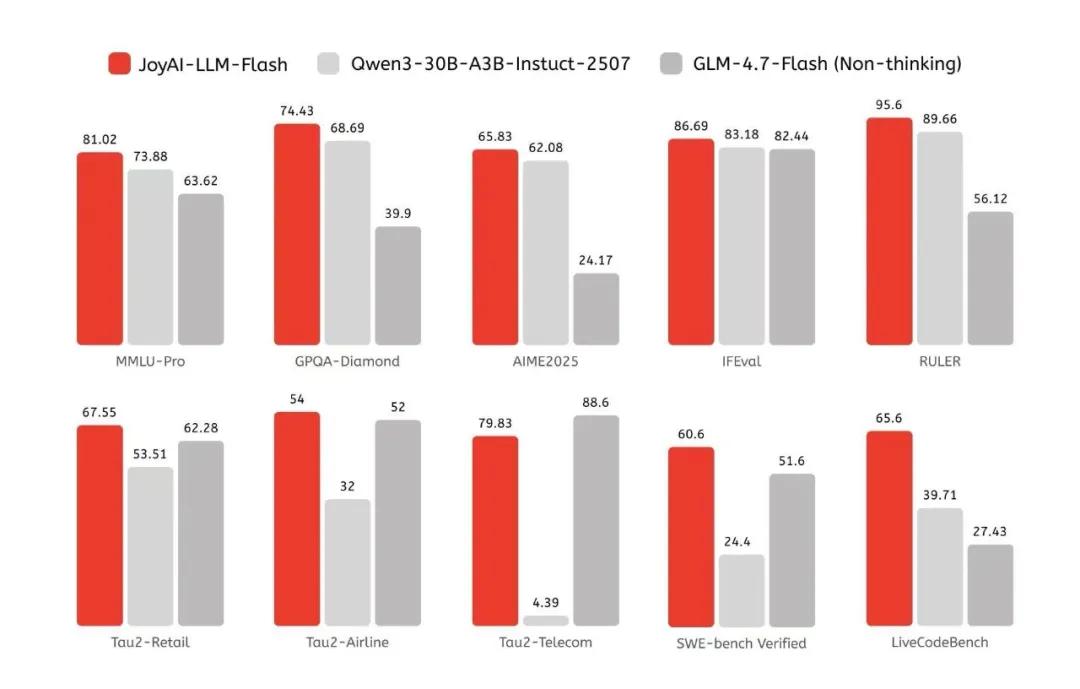
从定位来看,JoyAI-LLM Flash属于中量级模型——比百亿级模型更强,但远未达到千亿级模型的规模。这种定位决定了它的核心优势不在于"参数大",而在于"效率高"。京东官方数据显示,通过Muon优化器和MTP技术,推理吞吐量较标准版本提升1.3至1.7倍。
评价一款模型的实力,需要放在同级别竞品的坐标系中对比。
京东官方提供了与Qwen3-30B-A3B和GLM-4.7-Flash的对比数据,以下是几个关键指标:
| 基准测试 | JoyAI-LLM Flash | Qwen3-30B-A3B | GLM-4.7-Flash |
|---|---|---|---|
| MMLU | 89.50 | 86.87 | 80.53 |
| MMLU-Pro | 81.02 | 73.88 | 63.62 |
| HumanEval | 96.34 | 95.12 | 74.39 |
| LiveCodeBench | 65.60 | 39.71 | 27.43 |
| MATH 500 | 97.10 | 89.80 | 90.90 |
| SWE-bench | 60.60 | 24.44 | 51.60 |
从数据来看,JoyAI-LLM Flash在多数测试中确实优于这两个竞品,但差距幅度并不一致。
在MMLU上领先约3%,在LiveCodeBench上领先超过25个百分点,而在HumanEval上三者的差距很小。需要注意的是,这些基准测试成绩由京东官方提供,尚未经过第三方独立验证。实际落地效果如何,需要更多社区反馈和真实场景测试。
JoyAI-LLM Flash有几项值得关注的技术细节:
纤维丛强化学习(Fiber Bundle RL)是其中最具特色的创新。京东将数学中的纤维丛理论引入强化学习,提出FiberPO优化框架,专门解决大规模异构智能体训练中的稳定性和鲁棒性问题。这在业内属于较新的尝试,不过目前相关论文和详细技术资料尚未公开,外界难以深入评估其实际效果。
训练数据构成方面,京东透露使用了20万亿token进行预训练,中训练阶段重点增强了代码、智能体推理和长上下文能力。但与行业惯例不同,京东未公开训练数据来源的具体构成,这使得外界难以判断模型在哪些领域具备优势。

相比纯技术参数,用户可能更关心这东西能干什么。
京东在产业场景上的积累是客观事实:
- 京东数字人已服务超过20000个品牌直播间,支持24小时不间断带货,成本约为真人直播的十分之一
- 京东物流超脑累计调用超过13亿次,覆盖数十个物流业务场景
- 千万级SKU的库存周转天数优化至约30天
这些数据来自京东官方披露,反映了其在供应链场景的落地深度。但需要指出的是,这些成果是整个JoyAI产品矩阵的贡献,并非单独来自JoyAI-LLM Flash这一个模型。
整体来看,JoyAI-LLM Flash是一款有竞争力的中量级开源模型。其优势在于:推理效率优化做得扎实,在智能体和代码生成任务上的表现优于同级别竞品,与京东产业链结合紧密。
对于有意尝试的开发者,JoyAI-LLM Flash提供了vLLM和SGLang两种部署方案,技术门槛不算高。还可以通过京东云平台便捷地访问JoyAI-LLM Flash的API服务,该API兼容OpenAI和Anthropic的开发接口,可以轻松地将模型能力集成到现有应用中。
参考资料:https://huggingface.co/jdopensource/JoyAI-LLM-Flash
 豫公网安备41010702003375号
豫公网安备41010702003375号