
别被Demo骗了,Anthropic拆解了百万次交互,告诉你AI Agent落地的残酷现状
![]() 前沿资讯
1771492476更新
前沿资讯
1771492476更新
![]() 67
67
Anthropic 发布了一篇关于 Agent 自主性的报告。
我翻完了全文,最大的感受不是“AI 变强了”,而是“我们之前对 Agent 的理解可能全错了”。
很多人觉得 Agent 就是给大模型套个工具壳,让它自己跑。但如果你真负责过生产环境,你心里肯定有个过不去的坎:这玩意儿到底能撒手多久?
报告里提到了一个 Claude Code 的数据:长会话的自主运行时间从 25 分钟翻倍到了 45 分钟。
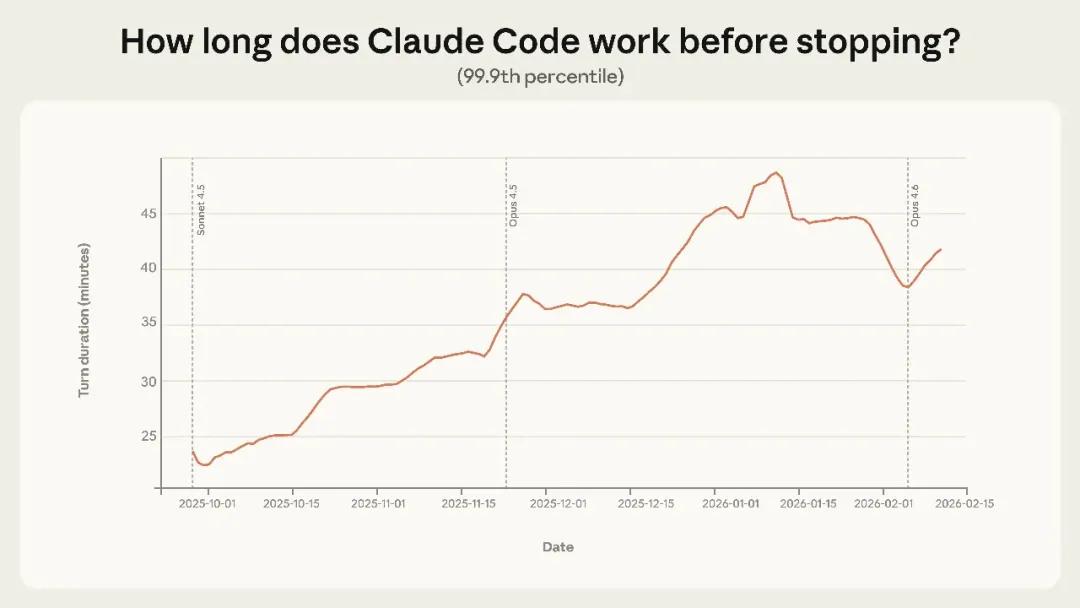
别误会,这 45 分钟不是 AI 在那儿发呆,而是实打实地在你的代码库里翻文件、跑测试、改 Bug。最有意思的是,这个增长曲线非常平滑。这说明什么?说明这不全是模型变聪明了,而是我们这些写代码的,终于开始学着跟 AI 磨合了。
但尴尬的是,理论上像 Claude 4.5 这种级别的模型,在实验室里能处理 5 小时的任务,但在现实里,大家用到 40 多分钟就得停一下。这种“理论 5 小时,现实 40 分钟”的部署鸿沟,才是现在 Agent 落地的真实困境。
我最喜欢报告里关于“老鸟”和“新手”对比的那部分。
新手用 Agent,恨不得每一行 git commit 都要盯着看,只有 20% 的人敢开全自动。这不叫用 Agent,这叫找了个祖宗。
而那些用了几百次的老司机,全自动比例直接拉到了 40% 以上。但这并不代表他们躺平了,相反,老司机的“打断率”反而更高。
这才是真正的工程思维:我不预审你的每一行逻辑,但我盯着你的输出结果。 一旦发现 AI 开始绕圈子或者逻辑跑偏,老司机的手速比谁都快。这种“高频率打断+高程度授权”的矛盾组合,其实就是未来 AI 时代的管理者画像。
大家都在说 Agent 是未来,但看一眼调用比例:50% 还是在写代码。
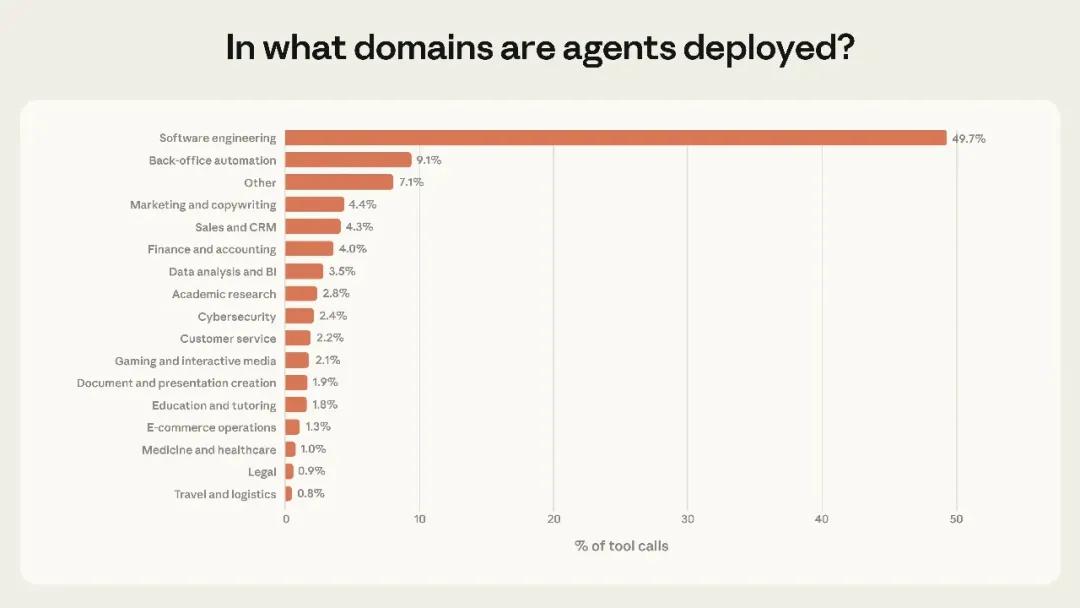
报告里有个数字很诚实:在所有 API 调用里,不可逆的操作(比如真发了一封邮件出去,或者划走一笔钱)只占 0.8% 。
这才是真相。写代码能火,是因为有 Git,有测试环境,大不了代码写烂了回滚。但在金融、医疗这种地方,那 0.8% 的不可逆操作就是生死线。只要这 0.8% 的风险解决不了,Agent 在这些领域就只能永远当个“建议官”,进不了决策层。
还有一个挺反直觉的点:Agent 停下来,往往不是因为我们要它停,而是它自己怕了。
在复杂任务里,Claude 主动提问的次数是人类打断它的两倍。它会问你:“这两种方案你选哪个?”或者“我没权限看这个库,你能不能帮我开一下?”
这其实是件好事。比起一个闷头把你的服务器删了的“勤奋型 AI”,这种会认怂、会止损、会问“你确定吗”的 Agent,才是真正能进生产环境的战友。
看完这份报告,如果你正打算给自家业务配 Agent,别光顾着卷模型参数。
真正拉开差距的,是报告最后提到的那套“后部署监控体系”。你得能看见它在干什么,得能在它跑偏的 45 分钟里随时接管。
总结一句话:Agent 的上限看模型,但下限绝对看你的工程基础设施盖得稳不稳。
参考资料:https://www.anthropic.com/research/measuring-agent-autonomy
 豫公网安备41010702003375号
豫公网安备41010702003375号