
你花三天整理的Agent.md,可能正在让AI编程变笨,研究显示,塞的越多,问题越多
![]() 前沿资讯
1771929040更新
前沿资讯
1771929040更新
![]() 66
66
你有没有发现,大家都在用AI写代码,你也在跟着学,但用起来就是没有别人那么顺?
问题可能不在于你用的AI不对,也不在于你不够努力,而在于:你认真写的那些"使用说明书",可能正在帮倒忙。Theo - t3.gg用主流大模型做了对比测试,得出的结论是:
我们花了巨大心思整理的规范文件,不仅没用,反而让AI变笨了。
先做个假设实验。
你招了一个名校毕业的程序员,能力很强,代码写得漂亮。
但每次他动手之前,你都要塞给他一份200页的"工作指南",里边有公司文化、代码规范、每个项目的历史沿革、技术选型的理由、历任维护者的八卦……事无巨细,应有尽有。
然后你发现,他的工作效率变低了,bug变多了,经常在一些莫名其妙的地方卡住。
你会怎么想?大概率会觉得自己写的那份指南有问题吧?
但如果我们把"新来的程序员"换成"AI编程助手",把"200页指南"换成"Agent.md / Claude.md",事情就变得魔幻了:几乎所有人都在这么做,而且没人觉得有问题。
这就是当前AI编程圈的现状,也是这项研究要捅破的那层窗户纸。
让我们先回溯一下这段"歧路"是怎么形成的。
2022年,ChatGPT横空出世,大家开始用它辅助写代码。那时候很简单,就是在prompt里写几句指令:"你是一个Python专家,请帮我写个函数。"
后来模型越来越强,大家的需求也越来越复杂。简单的指令不够用了,怎么办?
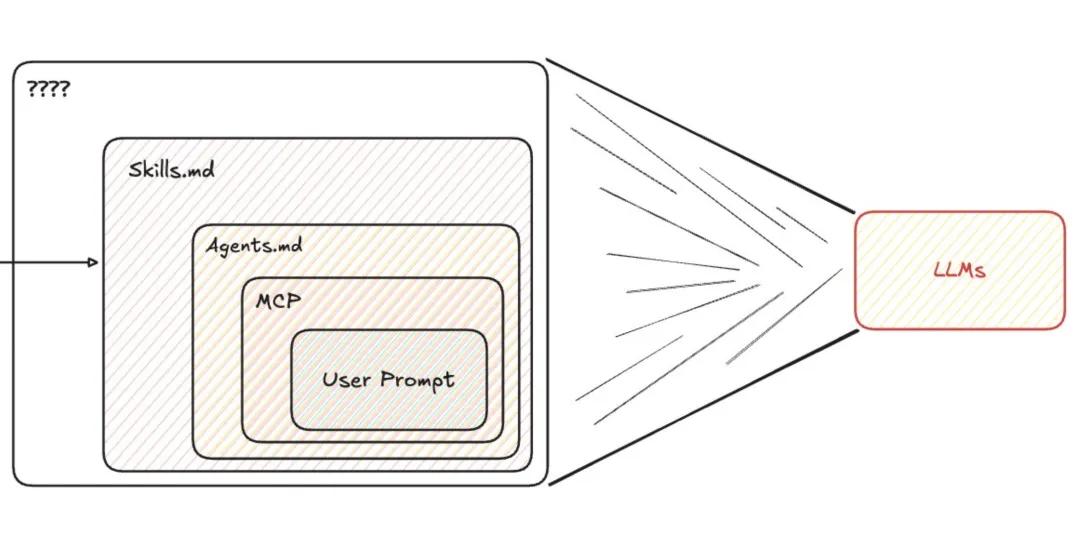
第一层:Instructions.md
聪明人想出一个办法,与其每次都重复写一样的指令,不如写一份"通用说明书",每次传给AI。这份文件后来演变成了Instructions.md。
但好景不长。AI要干的活越来越复杂,从"写个函数"变成了"帮我把这个旧项目从Java 8升级到17,还要重构三个模块的依赖关系"。简单的说明书不够用了。
第二层:Agents.md / Claude.md
这时候,更"专业"的方案登场了。告诉AI"你是谁、你该做什么、你不该做什么、遇到特殊情况该怎么处理"。于是,每个团队都开始给自己的项目写一份详尽的"法规",也就是今天我们要讨论的Agent.md或Claude.md。
再后来,Anthropic推出了MCP(Model Context Protocol),OpenAI推出了自己的Agent规范,业界又冒出了Skills.md……每一种都声称自己是"更优雅的解决方案"。
但问题来了,这些方案的本质是什么?
用一位从业者的话说:说白了,我们只是在换着花样给AI塞更多的字符串。
那为什么塞得越多,问题越多?
有一个这样的比喻。
你是一个长途货车司机,要从北京开到上海。有人给你塞了一本《中国高速公路大全》,让你"务必仔细阅读,了解每一段路的来龙去脉"。
你会怎么做?
大概率是随便翻两页,然后扔到一边,按自己的经验开。
因为信息太多等于没有信息。真正对你有帮助的,可能只是导航仪上的那一小条路线提示。
AI也是一样的道理。
Anthropic最初推出的MCP,思路是给AI提供"全面的上下文",每个MCP服务器在实际的prompt之前要塞入多达6万个token。
想象一下:你想问AI"帮我写个登录接口",但AI在回答之前,必须先"读完"一本半《战争与和平》那么长的背景资料。
结果是什么?AI的幻觉率飙升,上下文窗口被撑爆,成本急剧增加。 典型的"好心办坏事"。
Anthropic后来自己也发现了这个问题,改弦易辙,不再给AI塞上下文,而是让AI生成可执行的代码,让代码自己跑出结果再反馈回来。这本质上是在承认:上下文填充这条路,走不通。
再来看Agent.md。比起MCP,它的"姿势水平"看起来更高。不再是机械地堆砌信息,而是"有组织地教导AI"。
但问题在于,随着项目增长,这份"教导文档"会无限膨胀:
- 新增了一个模块?更新Agent.md。
- 修改了技术选型?更新Agent.md。
- 来了个新人,提了建议?更新Agent.md。
日积月累,这份文件变成了一份"历史档案",混杂着过时的信息、矛盾的指令、无人敢删的"遗留资产"。新来的AI读完之后,只会更糊涂。
一位开发者吐槽道:这就像给一个成年人塞一份从小学到高中的所有作业评语,然后指望他写出更好的作文。
说了这么多,让我们回到开头提到的那项研究。
研究者做了两件事:
第一,用真实场景测试。 他们选择了真实的代码库issue,包含开发者实际commit的Agent.md文件。
第二,覆盖主流大模型。 测试对象包括目前市面上主流的几款大模型,确保结论不是"某一家不行",而是具有普遍性。
结论是什么?
绑定了Agent.md文件的AI编程助手,任务完成准确率出现了系统性下降。
不是"差不多",不是"因人而异",是"一致性地更差"。
更扎心的是,研究者还发现了一个现象:很多团队在使用这些文件时,连生成方式都是错的。要么是自动生成后没有人工审核,要么是参考了其他项目的模板却没有适配自己的场景。
这就好比:你在网上找了一份"健身计划",没仔细看就照着练,结果不仅没瘦,还扭伤了腰。
如果你是一个普通开发者,这项研究指出了三件事:
第一,你之前写的那些规范文件,大概率是在浪费时间。
不是说你写得不好,而是这种方式本身可能就有问题。就像你给跑步机通上电想让它往前走,它纹丝不动,不是你操作的问题,是产品设计的问题。
第二,你不必焦虑于"还没写Agent.md"。
很多开发者看到别人都在分享自己的Agent.md模板,会产生一种"落后了"的焦虑。现在你可以放心了,没写可能是对的,写了反而可能帮倒忙。
第三,是时候重新思考"怎么和AI合作"了。
这项研究不是要我们放弃AI编程助手,而是要我们换一种思路。与其写一份冗长的"使用说明书",不如只给AI真正需要的关键信息。
既然,上下文填充是死路,那正确的路在哪里?
研究者和行业老炮们的建议是:回归精简,回归上下文管理的本质。
具体来说,可以参考以下几个原则:
原则一:只给AI需要的信息。
一份README.md能说清楚的事,就别写一份Agent.md。AI不是需要"知道一切",而是需要"明确需求,知道要做什么"。
原则二:保持更新,避免信息过时。
如果非要写规范文件,请确保它随着项目一起演进。过时的指令比没有指令更危险,因为它可能会给AI提供错误的方向。
原则三:相信模型的基本能力。
如今的大模型已经具备了相当强的上下文理解和推理能力。它们不需要你事无巨细地"教导",只需要在关键时刻给出正确的方向。
原则四:用执行代替描述。
与其告诉AI"你应该怎么做",不如给它一个能够直接执行的框架,让它自己推理出路径。这正是Anthropic后来改进MCP的思路。
从System Prompt到Instructions.md,再到Agents.md、MCP、Skills.md……
我们似乎一直在发明新的"轮子",试图让AI更好地为我们工作。但这项研究提醒我们:有时候,不作为比乱作为更好,少即是多。
当然,这并不是要全盘否定所有的规范工作。
有些场景下,结构化的上下文确实能帮助AI理解复杂的代码库。
问题的关键在于:我们需要问自己一个问题:我给AI的这些信息,真的是它需要的吗?还是只是让我自己感觉"我已经尽力了"?
如果你能诚实地面对这个问题,也许会发现:真正的答案,往往比想象中简单得多。
参考资料:https://x.com/theo/status/2025900730847232409;https://x.com/avrldotdev/status/2025901389596266498
 豫公网安备41010702003375号
豫公网安备41010702003375号