
Gemini 3.1 Flash TTS 发布:Google 推出史上最具表现力的 TTS 模型,Elo 达 1211
![]() 前沿资讯
1776328935更新
前沿资讯
1776328935更新
![]() 1
1
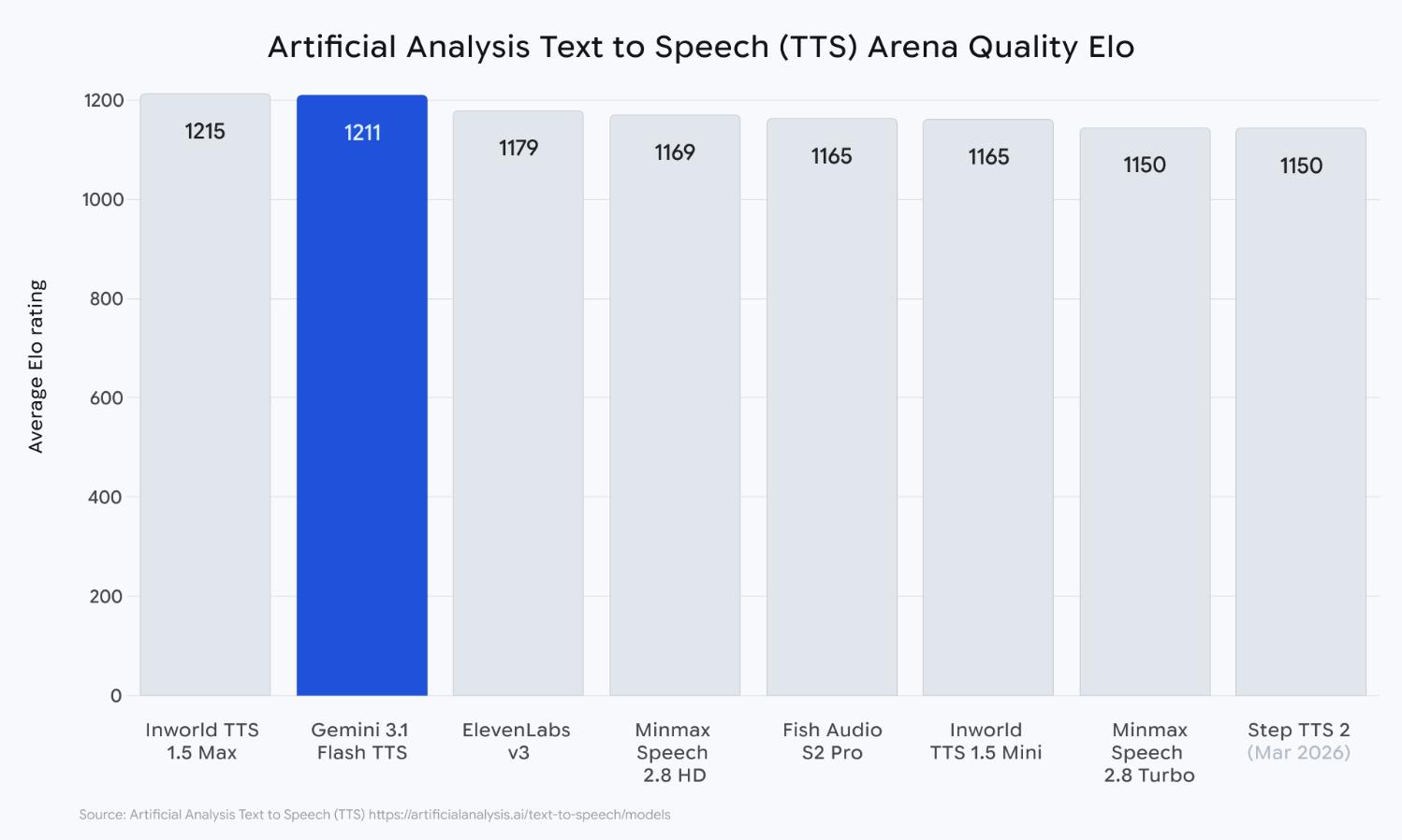
Google 今日正式发布 Gemini 3.1 Flash TTS,这是其最新一代文本转语音模型,在可控性、表现力和音质上实现全面突破。 该模型已在 Artificial Analysis TTS 排行榜中以 1211 Elo 的成绩位列前茅,并凭借"高质量+低延迟+低成本"的组合优势进入"最具吸引力象限"。
TL;DR
- 【突破性音质】 Artificial Analysis TTS 排行榜 Elo 1211,进入"最具吸引力象限",胜任 70+ 语言多风格语音生成
- 【音频标签控制】 首创 Audio Tags 技术,通过自然语言指令精准控制语速、语调、情感和角色切换
- 【企业级安全】 SynthID 数字水印全覆盖,AI 生成音频可溯源,从源头防止虚假信息传播
技术规格表
| 参数 | 规格 |
|---|---|
| 模型名称 | Gemini 3.1 Flash TTS |
| Elo 分数 | 1,211(Artificial Analysis TTS 排行榜) |
| 支持语言 | 70+ |
| 对话支持 | 原生多说话人对话(Multi-speaker Dialogue) |
| 核心控制方式 | Audio Tags(音频标签,自然语言嵌入) |
| 安全机制 | SynthID 数字水印(内置于音频输出) |
| 开发者预览 | Gemini API、Google AI Studio |
| 企业预览 | Vertex AI |
| Workspace 用户 | Google Vids |
| AI Studio Playground | 支持可配置控制面板(场景方向、说话人配置、导出代码) |
| 排行榜定位 | Artificial Analysis "Most Attractive Quadrant"(高质量 + 低成本) |
核心功能拆解
1. Audio Tags:自然语言驱动的语音控制革命
Gemini 3.1 Flash TTS 引入的 Audio Tags 是本次发布的最大亮点。开发者无需依赖复杂的 SSML 标签或 API 参数,只需在输入文本中嵌入自然语言指令,即可精准控制语音输出的每一个细节。
可实现的控制维度包括:
- 场景方向(Scene Direction): 定义环境背景和对话情境,帮助角色始终"入戏"并自然回应多轮对话
- 说话人级配置(Speaker-level Specificity): 为每个角色分配唯一音频档案,通过 Director's Notes 调整语速、语调和口音;使用内联标签还可在句中切换情感表达
- 无缝导出: 调试完成后,所有参数可直接导出为 Gemini API 代码,确保跨项目和跨平台的声音一致性和可识别性
2. 70+ 语言与全球化语音体验
该模型针对主要市场进行了核心优化,将高级风格、节奏和口音控制带到全球开发者面前。原生多说话人对话能力使构建本地化、富有表现力的语音应用成为可能——无论是多角色有声内容还是跨语言语音助手,都能保持一致的自然度。
3. 高保真音质与成本效率的平衡
在 Artificial Analysis 的盲测评估中,Gemini 3.1 Flash TTS 获得了 1211 Elo 的高分。更重要的是,它同时进入了该榜单的"最具吸引力象限"——这是对"高质量语音生成"与"低使用成本"这对通常矛盾目标的最佳平衡认可。
安全与合规
所有由 Gemini 3.1 Flash TTS 生成的音频均内置 SynthID 数字水印。这一人耳不可感知的 watermark 直接嵌入音频输出层,支持可靠检测 AI 生成内容,从源头遏制虚假信息的传播。Google 已在模型卡(Model Card)中公开了安全与责任框架的详细信息,企业用户可将其纳入合规审计流程。
互动问答
Q1:Gemini 3.1 Flash TTS 和上一代相比,最核心的提升是什么?
A:最核心的提升是 Audio Tags 技术的引入——它允许开发者用自然语言指令直接控制语音的节奏、情感、角色切换和场景背景,这是 TTS 领域首次实现如此细粒度的"导演式"控制。结合 1211 Elo 的音质评分和 70+ 语言支持,新模型在表现力和全球化能力上都有质的飞跃。
Q2:SynthID 水印会影响音频质量或增加延迟吗?
A:不会。SynthID 水印是人耳完全不可感知的噪声嵌入,不影响音频的客观音质和主观听感,也不会显著增加合成延迟。Google 选择在音频生成层而非后处理阶段嵌入水印,正是为了在保证内容溯源能力的同时,不牺牲实时语音合成的使用体验。
 豫公网安备41010702003375号
豫公网安备41010702003375号