
OpenAI开源发布隐私信息检测工具Privacy Filter
![]() 前沿资讯
1776929459更新
前沿资讯
1776929459更新
![]() 0
0
OpenAI于当地时间22日开源发布了一款名为Privacy Filter的双向token分类模型。
该模型专注于个人身份信息检测与脱敏处理,可识别账户号码、私人地址、电子邮件、姓名、电话号码、URL、日期及密钥等8类隐私信息,旨在帮助企业实现数据清洗流程的高效化与合规化。
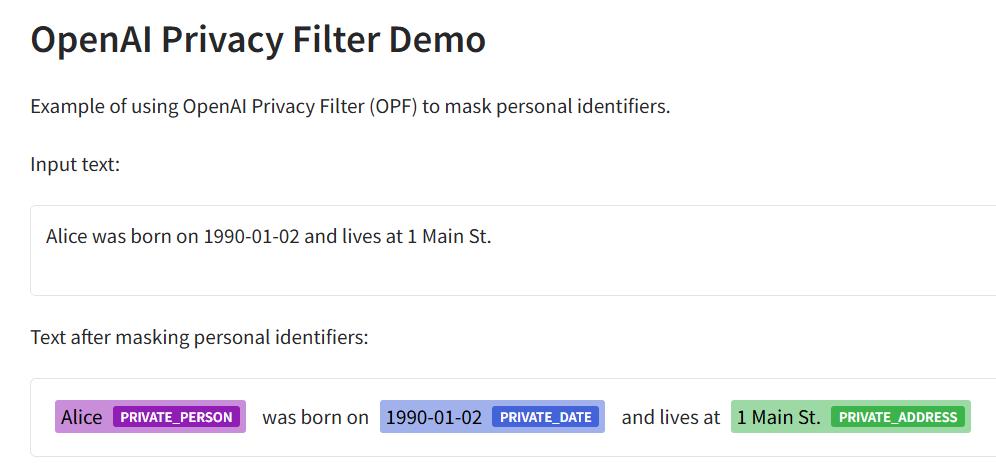
据悉,该模型参数量为1.5B,其中活跃参数约5000万,可在浏览器或笔记本电脑上本地运行。Privacy Filter提供128,000 token的上下文窗口,支持长文本一次性处理,无需分块操作。用户在运行期间可通过预设操作点调整召回率与精确率的平衡,灵活适配不同业务场景需求。
该模型采用Apache 2.0开源许可证,对实验研究、商业部署及定制化开发均不设限制。开发者可通过Python API或CLI命令行工具将其集成至现有数据管道,模型权重已上传至Hugging Face平台,开发者可免费获取。
技术层面,该模型基于类似gpt-oss的架构改造而来,采用有监督分类损失函数进行后训练。推理阶段运用约束Viterbi解码算法,将全局路径优化与局部token决策相结合,以BIOES标注体系对检测边界进行精确标注,确保脱敏区域连贯完整。
核心参数一览
| 项目 | 规格 |
|---|---|
| 模型类型 | 双向token分类模型 |
| 总参数量 | 1.5B |
| 活跃参数 | 约5000万 |
| 上下文窗口 | 128,000 token |
| 许可证 | Apache 2.0 |
| 检测类别 | 8类隐私信息 |
业内专家表示,随着数据隐私保护法规在全球范围内日趋严格,市场对高效隐私信息检测工具的需求持续增长。该工具的发布为企业在本地化部署场景下提供了新的选择,有助于降低数据泄露风险。
不过专家同时提醒,该模型应作为整体隐私保护方案的组成部分,而非独立的匿名化解决方案;在医疗、金融、法律等高敏感领域,仍需结合人工审核以确保处理效果。
 豫公网安备41010702003375号
豫公网安备41010702003375号