
Heretic:一行命令拆掉AI的过度限制,让模型不再畏手畏脚
![]() 工具推荐
1780198258更新
工具推荐
1780198258更新
![]() 0
0
之前有碰到一件事,现在想想还能气上半天。
我想让AI帮我看看一段代码有没有安全漏洞,就是那种XSS、SQL注入之类的常见问题。结果它直接拒了我,说"不能协助进行任何形式的网络攻击或渗透测试"。
我就:???
我就想知道自己写的代码有没有bug啊,又不是要去黑谁。检查自己代码的安全性,怎么就成"渗透测试"了?而且就算渗透测试,正经安全工程师天天都在干这事啊,怎么到我这儿就不行了?
但AI就是这么干了,礼貌而坚定。
相信用AI的朋友都懂这种感觉。你让它帮你写个爬虫抓点公开数据,它说"不能协助网络数据采集"。你让它帮你分析个可疑文件,它说"无法协助处理可能有害的代码"。你问它一道CTF题目怎么做,它直接来一句"不支持协助任何可能危害网络安全的活动"。
就好像每个AI背后都装了一个护栏,挡住了不该碰的内容。
问题来了:这个"护栏"到底藏哪儿了?
它不是一段代码,也不是什么开关。它分布在AI的无数参数里面,就像你的性格不是由某个器官决定的,而是整个大脑神经网络一起作用的结果。AI的"拒绝行为"也是这样,散布在几十亿到几百亿个参数之间,形成了一种"哪里不能碰"的直觉。
那能不能把这个"护栏"给拆掉?
能。而且挺神奇的。
最近我在GitHub上发现一个项目,叫Heretic,它能自动给AI模型拆掉它的"护栏",而且最骚的是,全程不需要你懂任何技术。
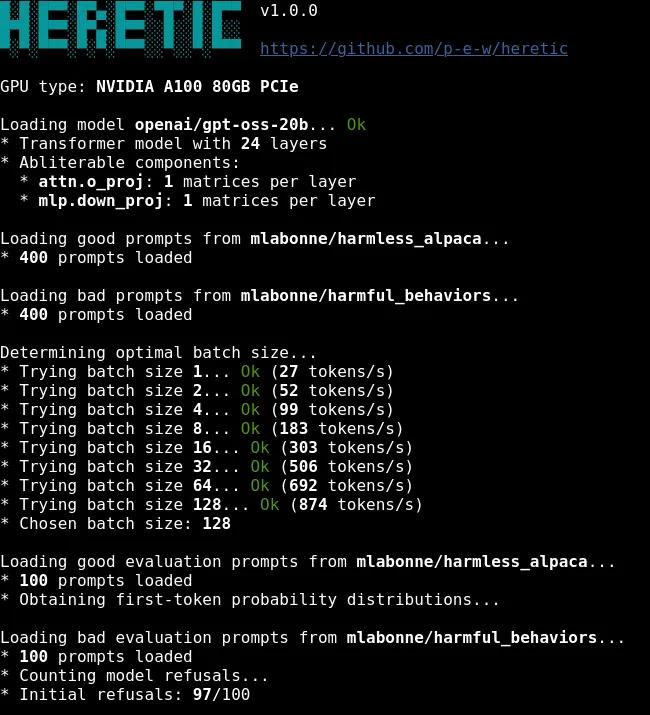
就两行命令:
pip install heretic-llmheretic Qwen/Qwen3-4B-Instruct-2507你把模型名字换成你想处理的模型,然后等着就行。
它会自动下载模型、分析它的拒绝模式、找到最佳参数配置、生成一个拆掉"护栏"的版本。整个过程大概二十到一个小时,具体要看你显卡性能。
关键是啥?这个过程完全自动化。你不需要懂transformer,不需要知道什么叫方向性消融,不需要调任何一个参数。就是一个命令扔出去,然后该干嘛干嘛。
等等,这里有个问题:拆掉"护栏"的AI,会不会变成危险分子?
说实话我一开始也担心。但看了原理之后,发现不是这么回事。
简单来说,Heretic做的事情,就是找到AI"拒绝回答"和"正常回答"之间的那个数学差异,然后用一种叫"方向性消融"的技术把这个差异给抑制住。
啥意思呢?我打个比方。
想象你有一台超级精准的天平。正常问题和敏感问题放上去,会往不同方向倾斜。方向性消融做的事情,就是找到这个倾斜的方向,然后对天平的关键结构做"校准"。不是让天平归零,而是让它对"敏感"那边的反应变得迟钝。
天平还是那个天平,能称东西,只是对"这算不算敏感"这件事不再那么敏感了。
这也是为什么项目用了Optuna来优化参数。它同时优化两个目标:最小化拒绝次数,同时最小化对模型能力的损伤。后面这个用KL散度来衡量,你可以理解为"处理后的AI和原版有多像",越低说明保留得越好。
作者给了对比数据。用Gemma-3-12B测试,原版面对100个敏感问题会拒绝97个。人工专家做的去限制版能拒绝3个,但KL散度是1.04。而Heretic自动生成的版本,同样能拒绝3个,KL散度只有0.16。
翻译成人话就是:0.16这个数字意味着,虽然AI不再拒绝回答那些"敏感"问题了,但它做其他事情的能力几乎没受影响。它只是不再绕弯子了。
社区已经用 Heretic处理了超过3000个模型,都放在Hugging Face上。你可以理解为,开发者们用这个工具给各种AI做了"无限制版",然后分享出来。
这项目还有个有意思的点:它能可视化研究。你可以看看AI在不同层级处理"有害"和"无害"问题时,它的内部表示是怎么变化的。意思就是,它不仅能帮你拆掉AI的"护栏",还能让你看到那个"护栏"长什么样。
从技术上说,这涉及到AI可解释性这个领域。研究者们一直想知道,大模型到底是"怎么想的",它的拒绝行为藏在哪里。方向性消融这个技术,某种程度上就是用"破坏性实验"来回答这个问题——我把这个区域的影响消除掉,看看会发生什么。
有意思的是,优化过程发现,AI的不同组件对这种"手术"的敏感程度不同。MLP层通常比注意力层更容易受影响,所以需要对它们分别设置不同的消融强度。这让整个过程更像是一门"微调艺术"。
最后说说我自己的感受。
我一直觉得,AI的"安全限制"是个挺拧巴的事情。一方面我们不希望AI被用来做坏事;另一方面,"有害内容"的边界到底在哪里?谁来定义?一个人觉得有害的东西,另一个人可能觉得只是正常需求。
而且还有个问题,就是"过度保守"。为了避免被骂,AI宁可多拒错,也不敢多说一句。结果就是,我们花了这么多算力训练的模型,遇到真问题时反而变得畏手畏脚。
当然我不是在说安全限制本身是错的,这个平衡很难把握。但至少,像 Heretic这样的工具存在,让我们看到了另一种可能:不是非此即彼的。
说到底,AI会拒绝,本身就说明它已经具备了某种判断能力。这种能力藏在哪里、怎么工作、能不能被调整——这些问题可能比"怎么让AI听话"更重要。
也许未来某天,我们对AI安全的理解足够深了,能做到更精细的控制:不是简单地装上或拆掉"护栏",而是让它真正理解什么是真正的伤害,什么只是让人不舒服的信息。
那时候,可能就不需要"拆护栏手术"了。
但在那之前,这个工具至少让我们看到了,AI的"限制"不是铁板一块,它是可测量、可分析、可调整的。
光是这一点,就挺有意思的,不是吗?
工具链接:https://github.com/p-e-w/heretic
 豫公网安备41010702003375号
豫公网安备41010702003375号