
智谱GLM-5.2正式发布并开源:1M无损上下文、MIT协议可商用、Code Arena开源第一
![]() 前沿资讯
1781678156更新
前沿资讯
1781678156更新
![]() 0
0
今天,GLM-5.2正式上线并开源。
相较于6月13日智谱宣布的面向GLM Coding Plan用户全量开放,现在,无论是个人开发者还是企业团队,都可以自由获取、使用和商用这一目前最强开源模型。
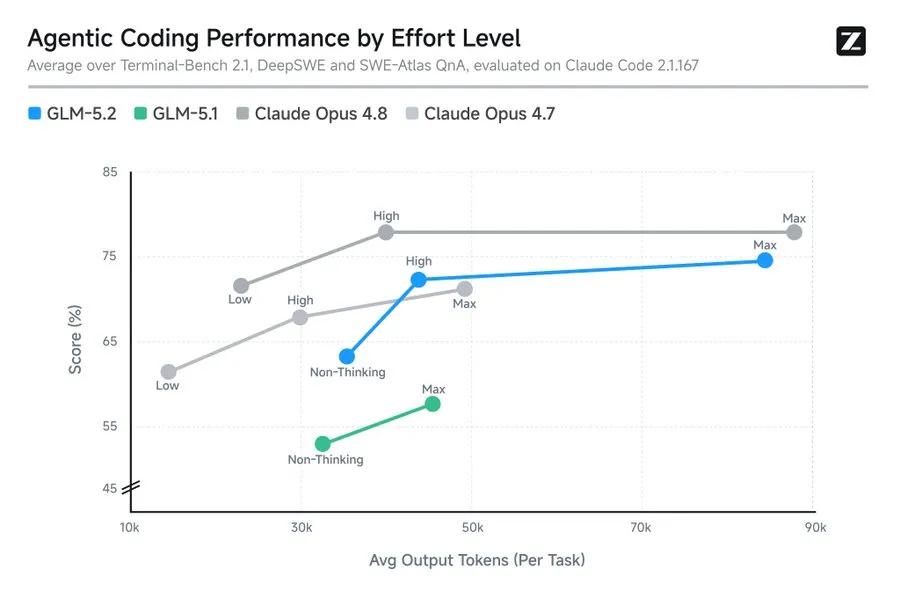
一、Solid 1M上下文,长程任务的基座
GLM-5.2实现了真正可用的1M无损上下文——不是"宣称支持"而是"工程上真正可靠"。
智谱表示,他们花了数月时间,专门针对1M Coding Agent场景进行强化训练,覆盖大规模代码实现、自动化研究,性能优化和复杂调试等多个高价值领域,使得GLM-5.2在1M上下文下的表现"有时甚至超越Opus"。
在三个长程任务基准测试中,GLM-5.2均位列开源模型第一:
| 基准测试 | GLM-5.2 | Claude Opus 4.8 | 说明 |
|---|---|---|---|
| FrontierSWE | 74.4 | 75.1 | 仅低1%,超过GPT-5.5和Opus 4.7 |
| PostTrainBench | 34.3 | 37.2 | 排名第二,仅次于Opus 4.8 |
| SWE-Marathon | 13.0 | 26.0 | 继续保持开源最高水平 |
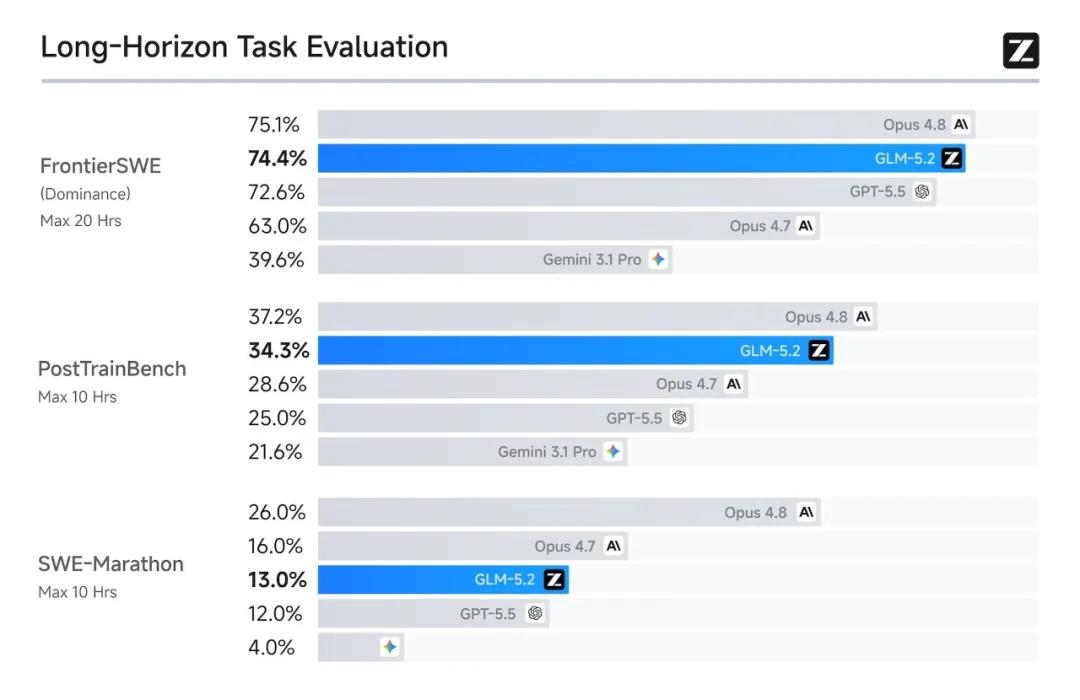
实测显示:GLM-5.2能够完成开发、联调、测试到打包上线的完整流程,交付一个覆盖Web、移动端与小程序的多端应用,累计处理88万Tokens——几乎用满了1M上下文窗口。这样的大型工程过去需要一支团队协作数周,现在GLM-5.2能在一次长程任务中跑完。
二、开源最强Coding能力
智谱表示,从2025年初开始,几乎投入全部力量攻关Coding。2025年中,代码基座GLM-4.5发布;年底的GLM-4.7已经成为效果最好的国产Coding模型。
本次在Code Arena等盲测平台上,GLM-5.2表现优异,据官方数据,该模型取得了全球可用模型第一的表现。
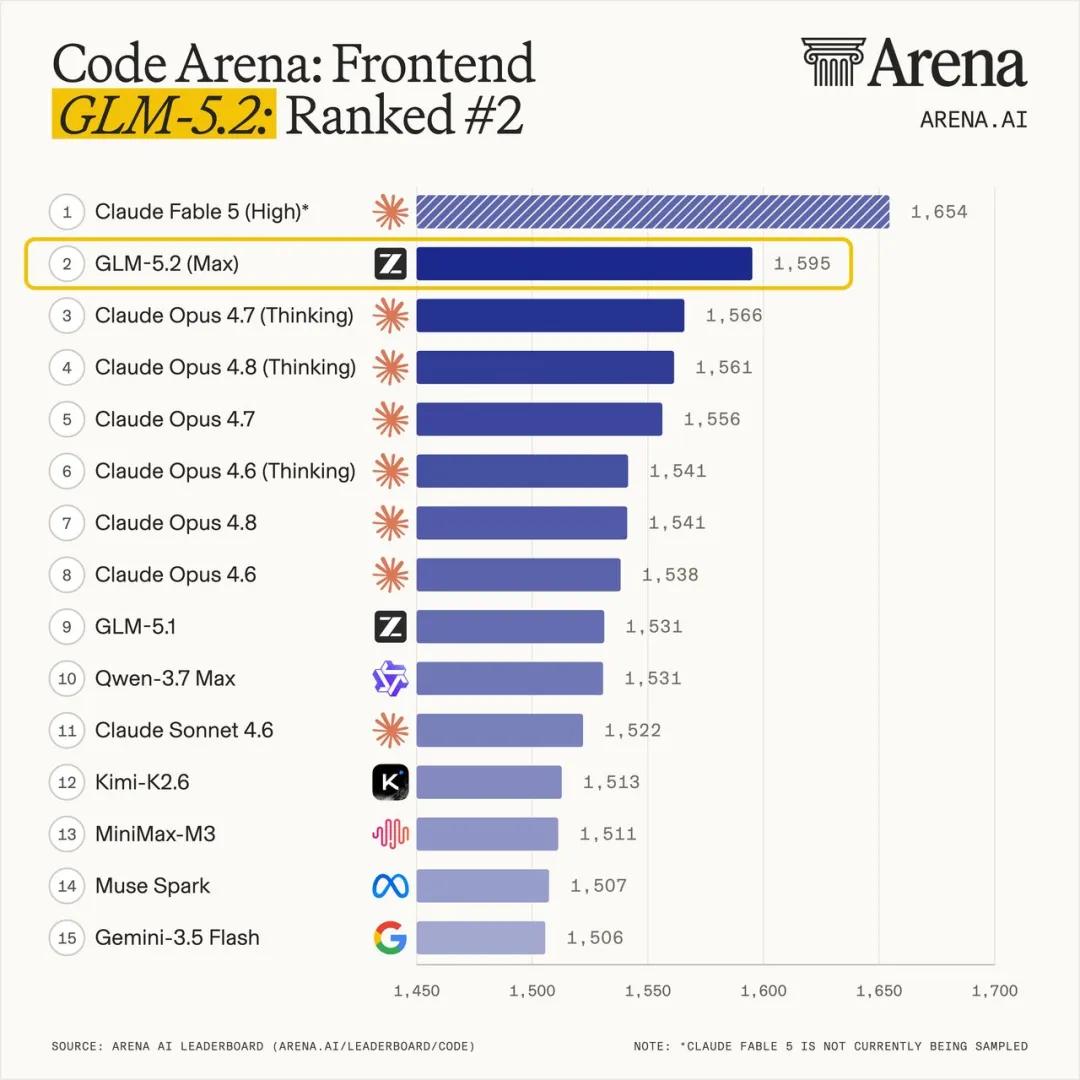
更值得关注的是"体感"——这是开发者实际使用中最直接的感受。有开发者用Rust从零再造了送人类登月的计算机,将当年65000行、一字未改的登月飞控程序移植为Rust,整个过程由Agent全自主走完。
此外,在Agent Arena(智能体综合评估平台)上,GLM-5.2排名第10,是排名最高的开源模型之一。
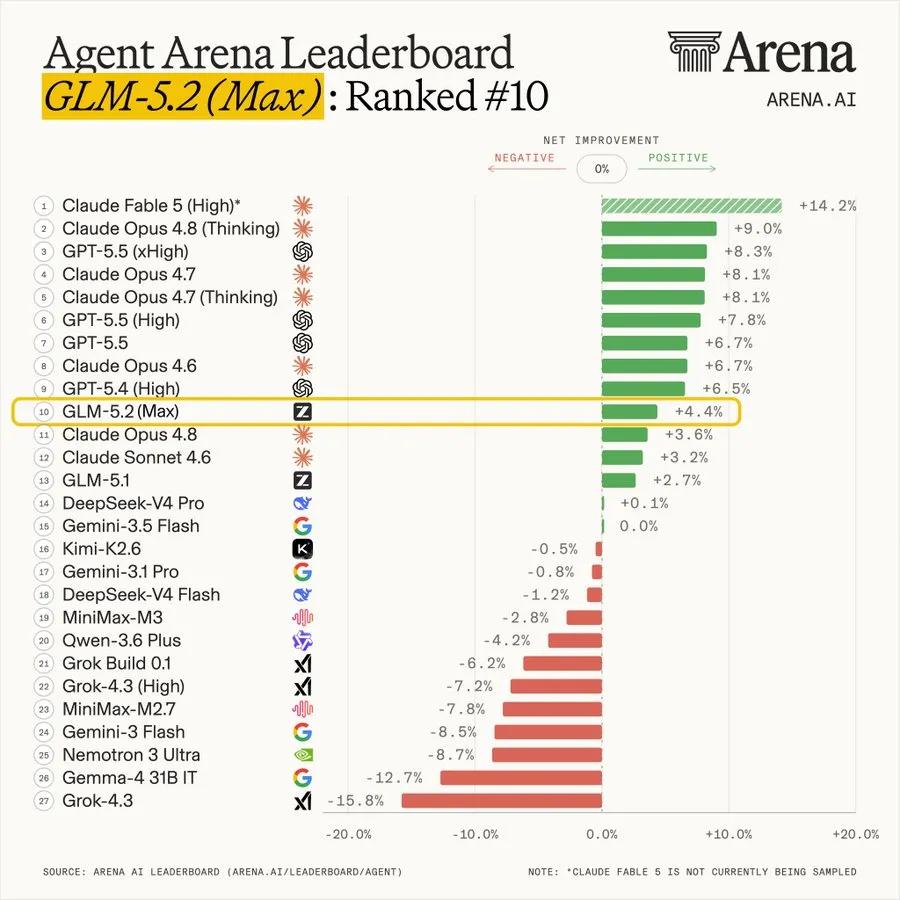
根据数十万开发者的反馈,GLM-5.2的提升主要体现在四个方面:
- 项目级上下文承载更强:能把完整工程放进同一条推理链路里
- 长程任务执行更稳定:复杂任务能持续推进,不容易中途跑偏
- 生产级工程规范遵循更可靠:能守住团队研发流程里的硬约束
- 客户端与移动端工程能力更扎实:不止写App,还能完成真机调试闭环GLM-5.2还引入了"思考档位"(effort level)控制功能,用户可以在能力、速度和成本之间做出平衡。在相近的token预算下,GLM-5.2的Coding能力大致位于Claude Opus 4.7与Claude Opus 4.8之间。
三、技术架构的创新
GLM-5.2的进步来自于三个层面的协同优化:模型本身、推理系统、训练方法。
IndexShare技术
这是智谱提出的一种创新架构优化。在传统的大语言模型中,每个注意力层都需要独立的"索引器"来计算和存储信息。而IndexShare技术让每4层稀疏注意力层共享同一个索引器——这就像4个人共用一个图书管理员,不需要每个人都有自己的管理员。
这项技术使得在1M上下文长度下,模型处理每个token的计算量降低为原来的约1/2.9(即计算效率提升2.9倍),大幅提升了推理效率。
MTP层优化
智谱还改进了用于投机解码(Speculative Decoding)的MTP层。投机解码是一种"先用小模型草稿,再用大模型校验"的加速技术,可以显著提升推理速度。GLM-5.2的MTP层优化后,投机解码的接受率提升20%,这意味着更快的推理速度和更高的效率。
推理引擎的三层优化
为了高效服务1M上下文,智谱对推理引擎进行了三个方向的优化:
- KV-cache容量优化:在LayerSplit基础上引入更细粒度的内存管理和并行策略,为超长上下文请求提供更多可用缓存空间
- 长上下文内核优化:优化随着上下文长度增长而成本增加的内核,更好协调缓存传输管道,最小化缓存传输对prefill和解码性能的影响
- CPU端优化:优化CPU端缓存管理、请求调度和运行时执行路径,减少GPU执行管道中的气泡,提升端到端吞吐量结果显示,随着上下文长度增长,GLM-5.2的吞吐量优势越来越大,在长上下文推理场景中展现出更强的可扩展性。
Anti-Hack模块
Coding强化学习中,Agent可能"走捷径":直接读取测试答案、从GitHub复制代码。
Anti-Hack模块采用两步检测:
- 规则过滤:抓可疑行为(比如访问不该访问的文件)
- LLM判断:确认是不是真的在"作弊"
发现作弊时,不是直接终止,而是返回假信息,同时让训练继续——避免模型因突然停车而"晕车"。
Slime框架
传统训练一个Coding模型需要数周,Slime框架把时间压缩到约2天。
它支持多种训练模式——可以自学(白盒)、模仿专家(黑盒)、高效压缩(紧凑轨迹)等,像一个高度自动化的"模型工厂"。
更重要的是,训练时积累的经验可以直接复用到生产环境——训练侧和服务侧形成闭环,互相增强。
四、开源与使用方式
开源协议:GLM-5.2采用MIT开源协议,这是最高权限的开源协议——可自由下载、部署与商用,无任何地域限制。
开源地址:
- GitHub:https://github.com/zai-org/GLM-5
- Hugging Face:https://huggingface.co/zai-org/GLM-5.2
- ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5.2API接入:
- Z.ai平台:https://docs.z.ai/guides/llm/glm-5.2
- 智谱BigModel平台:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.2在线体验:
- Z.ai:https://chat.z.ai
- 智谱清言App/网页版:https://chatglm.cnAPI定价(国内):
| 模型 | 上下文 | 输入 | 输出 | 缓存存储 | 缓存命中 |
|---|---|---|---|---|---|
| GLM-5.2(新品) | 1M | 8元/百万Tokens | 28元/百万Tokens | 免费 | 2元/百万Tokens |
| GLM-5.1(短文本 ≤32K) | 32K | 6元/百万Tokens | 24元/百万Tokens | 免费 | 1.3元/百万Tokens |
| GLM-5.1(长文本 >32K) | 128K | 8元/百万Tokens | 28元/百万Tokens | 免费 | 2元/百万Tokens |
注:缓存存储目前限时免费。
五、GLM Coding Plan:适合不同开发者的订阅套餐
Lite套餐
- 价格:¥49/月(连续包季约¥44.1/月)
- 定位:面向轻量级小仓库迭代
- 功能:支持20+编程工具,包括Claude Code
Pro套餐
- 价格:¥149/月(连续包季约¥134.1/月)
- 定位:面向日常中型仓库开发
- 功能:包含Lite全部功能,5倍Lite用量,优先获取最新旗舰模型和功能,包含精选MCP工具,更快的生成速度
Max套餐
- 价格:¥469/月(连续包季约¥422.1/月)
- 定位:面向中大型仓库的高级用户
- 功能:包含Pro全部功能,20倍Lite用量,峰值时段专属资源保障
团队套餐
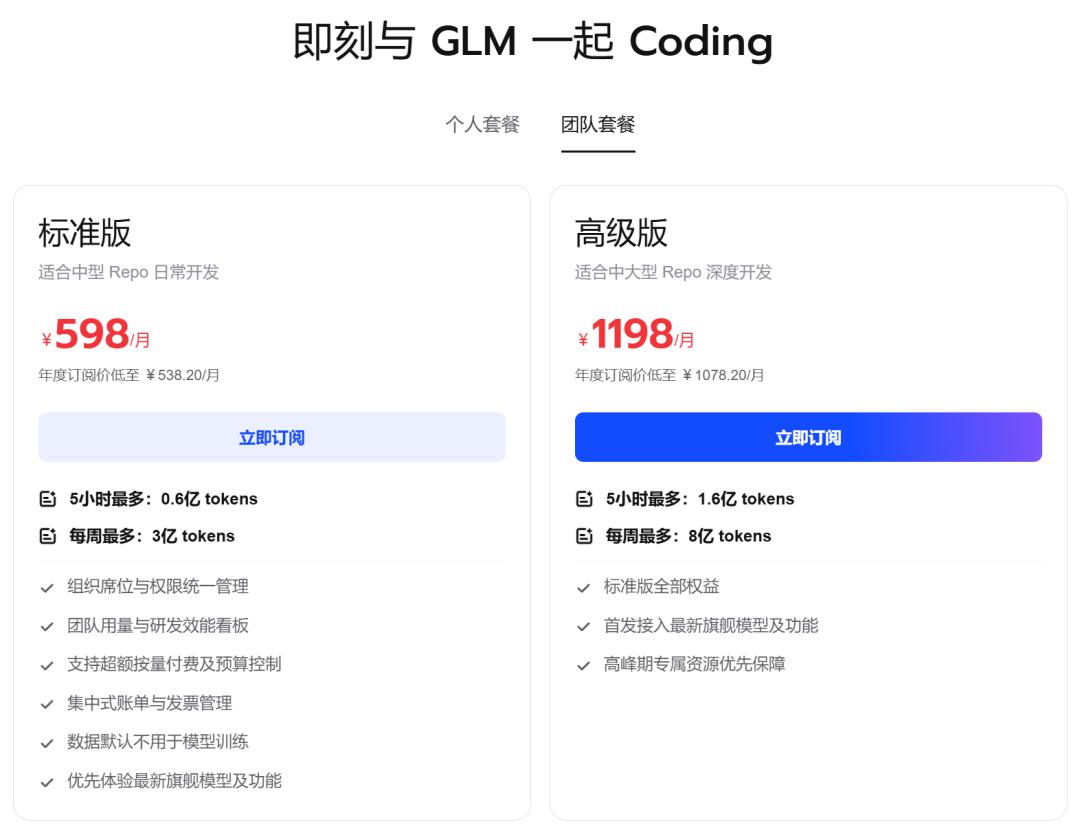
六、从"智能助手"到"数字员工"
在发布长程任务能力的同时,智谱也展望了更远的未来。
"代码还不是AGI,在通往AGI的路上,还有更多的高山需要翻越。"智谱介绍道。
下一个目标是"完全自治的智能体系统"(Autonomous Agent System)。基于长程任务之上,让AI能够自主驱动、协同作业、7×24小时运转的智能体群体将成为新的生产力形态。
从"智能助手"走向"数字员工",构建包含成千上万个不同专业"性格"与"技能"的智能体社会,让它们自主辩论、协作、审查代码、调度资源,实现"自动驾驶"级别的数字生产力——这将是智谱下一步攻克的方向。
GLM-5.2的发布,不仅是智谱AI技术实力的又一次展现,更体现了"前沿智能属于所有人"的理念。MIT开源协议、1M无损上下文、开源最强Coding能力,这些特性让每一个开发者都能站在同一起跑线上,用AI重新定义软件工程的工作方式。
相关资源:
- 技术博客:https://z.ai/blog/glm-5.2
- 技术报告:https://arxiv.org/abs/2602.15763
- GLM Coding Plan:https://z.ai/subscribe
- ZCode产品页:https://zcode.z.ai/
- AutoClaw产品页:https://autoglm.zhipuai.cn
 豫公网安备41010702003375号
豫公网安备41010702003375号