
AI Website Cloner:一条命令把任意网站变成干净的Next.js代码,平台迁移和源码学习有救了
![]() 工具推荐
1782959428更新
工具推荐
1782959428更新
![]() 0
0
你有没有遇到过这种情况——
突然看到一个网站,交互酷炫、设计精致,第一反应是"这帮人是怎么做出来的?"
然后你想学习一下,结果:F12打开控制台,代码是压缩成一坨的;找源文件,全是混淆过的变量名;想问问对方用的什么框架,估计没人会理你。
对,就是这种无力感。
但最近我发现了一个工具,可以解决这个问题。
准确说,是一个模板项目,叫 AI Website Cloner Template。
它的逻辑是这样的:你给它一个网址,它帮你把这个网站"扒"下来,生成一套干净的、可以直接跑起来的代码。不是截图拼图,不是Figma转代码那种,而是真的把每个按钮、每段动画、每个交互行为都给你拆解出来,然后用 Next.js 16 + React 19 + TypeScript + Tailwind CSS v4 + shadcn/ui 给你重新搭一遍。
这个工具能解决什么问题?
第一个场景,平台迁移。
假设你之前用的是WordPress、Wix或者 Squarespace,现在想换成Next.js自己搭。以前你可能得找前端一点一点重写,现在直接克隆一份,再慢慢改。
第二个场景,源码丢了。
这种情况其实挺常见的——外包做的东西,开发人员离职了,代码库也没了,网站还在跑。你想改点东西都不知道找谁。克隆一下,至少能拿回来一套能维护的代码。
第三个场景,学习。
这个我觉得是最香的。你看到某个网站的某个交互特别有意思,想学学它怎么实现的,直接克隆下来看源码,比你看十篇教程都有用。而且克隆出来的是 Tailwind CSS + shadcn/ui 组件,比那些压缩混淆后的代码好读一万倍。
克隆完你会得到什么?
这个才是我想重点说的。很多人以为克隆完就是一堆代码,其实远不止如此。
首先是一套可以跑的完整项目。
Next.js + Tailwind CSS + shadcn/ui 的架子已经搭好了,你直接 npm run dev 就能跑起来。TypeScript 严格模式,没有 any,类型安全。不需要从零配置开发环境。
然后是每个组件的"说明书"。
克隆过程中,AI会为每个组件生成一份 .spec.md 文件,里面记录了这个组件的精确参数:padding是多少、color是什么、hover状态怎么变化的、动画的触发条件是什么、duration和easing是多少。
这些东西才是真正值钱的。你去学一个网站的设计,不是看它用了什么颜色,而是看它为什么用这个颜色、这个间距、这个动画。这些说明书就是答案。
还有所有的原始素材。
图片、视频、图标、字体,全部下载到本地,按类别存在 public/images/、public/videos/、public/seo/ 这些目录里。你不需要再去找图片来源了。甚至包括那些"分层"的素材。
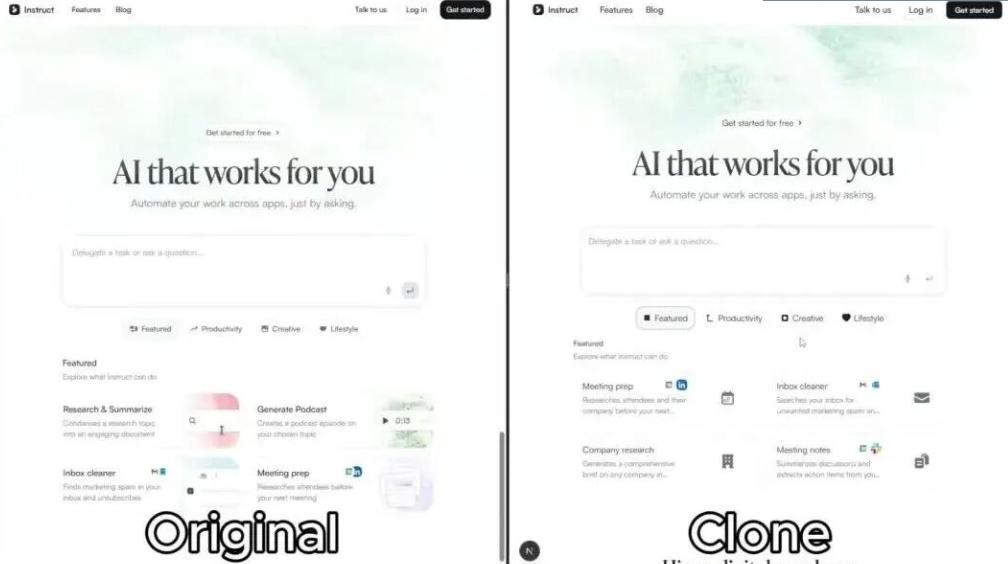
它是怎么做到像素级复刻的?
说起来原理不复杂,核心靠的是一个命令:/clone-website,后面跟一个或多个URL。
整个过程分五个阶段。
第一步,侦察。 AI会打开浏览器,把整个页面截图、提取颜色和字体、把所有的交互行为都过一遍,滚动、点击、hover,一个不漏。还会测试响应式布局,在桌面、平板、手机三个尺寸下分别观察页面的变化。
特别说一下,这步会记录动画是怎么实现的——是 IntersectionObserver 驱动?还是 CSS animation-timeline?还是 JS 监听 scroll 事件?duration 和 easing 是多少?这些都会被记录下来。
还有一个很实用的细节:判断交互类型的时候,AI会先滚动再点击。因为很多你以为的点击切换,其实可能是滚动驱动的。如果你先入为主当成点击交互来处理,后面发现是滚动驱动的话,整个实现得重写,很费时间。
第二步,建地基。 把全局样式、字体、图标、素材全部下载到本地。所有的颜色值、间距、动画参数都会转换成CSS变量存下来。图标默认用 Lucide React,但在克隆过程中会被替换成从目标网站提取的 SVG 图标。
第三步,写规范。 给每个组件写一份详细的"说明书",里面包含精确到像素的CSS值。这些规范以markdown文件的形式存在项目里,随时可以翻看。
第四步,并行构建。 不同的模块分给不同的AI agent同时去写。每个agent在独立的git worktree里工作,互不干扰。
第五步,组装和质检。 把各个模块拼起来,跑一遍视觉对比,看看跟原站一不一样。克隆结果和原站并排对比,哪里不对精确定位。只有通过质检,整个克隆才算完成。
还有一个原则贯穿全程:克隆阶段不做任何个人审美修改。颜色间距字体,1:1复刻原站。你觉得原站丑?先克隆下来,再说后面的事。
怎么安装和使用?
首先需要准备两样东西:Node.js 24以上,和一个AI编程助手。
它支持的工具挺多的——Claude Code、Codex CLI、Cursor、Windsurf、Gemini CLI、GitHub Copilot、Cline、Continue、Amazon Q 等等都能用。原作者推荐的是 Claude Code,配合 Opus 4.7 效果最好。
如果你的电脑上没有Node.js,或者懒得配置环境,可以用 Docker。项目里自带 docker-compose.yml,一条命令就能把整个开发环境跑起来。
具体步骤:
- 去 GitHub 点 "Use this template",创建你自己的仓库
- 把仓库克隆到本地
- 运行 npm install 安装依赖(或者用Docker)
- 启动你的AI编程助手,在命令行里执行 /clone-website 后面跟目标网址
# 克隆模板git clone https://github.com/你的用户名/你的仓库名.gitcd 你的仓库名# 安装依赖npm install# 启动AI编程助手# Claude Code需要配置浏览器自动化(见下方说明)claude --chrome# 运行克隆命令/clone-website https://目标网站.com关于 Claude Code 的浏览器自动化: 如果你用 Claude Code 的 --chrome 参数,需要安装 Claude in Chrome 扩展,并且需要一个付费订阅(Pro、Team或Enterprise)。国内用户如果访问不了 Claude 官方服务,这个方式可能不太适用,可以考虑其他支持浏览器MCP的工具。
# 或者用Docker,不用装Node.js# 开发模式跑在 3001 端口docker compose up dev --build一个省时间的技巧: 一次可以克隆多个网站。用空格分隔多个URL,AI会自动把它们分开存放,每个网站的结果在 docs/research/<域名>/ 下面,不会混在一起。
克隆的过程中你基本上就是在旁边看着就行。AI会自动完成侦察、提取、构建、质检的全流程。
最后说两句。
这个东西最让我觉得有意思的,不是"能克隆网站"这件事本身,而是它的方法论。它把逆向工程拆解成了一套可复用的标准化流程,任何人都能按照这个流程去操作。你学任何东西,都应该先想着怎么把它拆解成标准流程,而不是一上来就凭感觉东学一点西学一点。
更实用的是,克隆完成后,那些 .spec.md 文件会留在你的项目里。每个组件为什么这样设计、动画参数是什么、交互是怎么触发的,全部都有记录。这些才是真正值得反复琢磨的学习材料。
好的工具不只是让你省事,它还会倒逼你去学习一套更系统的做事方法。
 豫公网安备41010702003375号
豫公网安备41010702003375号