
OpenAI研究人员提出SimpleQA基准测试,旨在更有效地评估和提升语言模型在“事实性”的表现
![]() 工具推荐
1730448610更新
工具推荐
1730448610更新
![]() 0
0
在人工智能领域,提升语言模型生成准确事实回答的能力始终是一个尚未解决的挑战。当前的前沿模型有时会产生虚假的输出或未经证实的答案,这种现象被称为“幻觉”,这些幻觉是阻碍大语言模型等通用人工智能形式更广泛采用的主要障碍之一。“事实性”确实是一个复杂的议题,主要是因为对任意特定声明的真实性进行评估可能颇具难度,在现实世界中,信息的真实性验证是一个涉及多方面考量的过程,包括信息来源的可靠性、证据的支持度以及信息的一致性等,此外,语言模型在生成文本时常常会产出包含众多事实断言的长篇文本,这进一步增加了评估事实性的复杂性。长篇文本中可能包含数十个甚至上百个事实性声明,每个声明的验证都需要细致的审查和证据支持,这样的验证工作不仅耗时耗力,而且对于自动化系统来说,更是一个巨大的挑战。

为了简化问题并使衡量事实性变得更加可行,OpenAI的研究人员选择关注简短、寻求单一答案的事实查询,这样可以在一定程度上规避开篇文本中提到的复杂性,通过这种方式,研究人员希望能够更有效地评估和提升语言模型在事实性方面的表现。为此,研究人员提出了一个名为SimpleQA的基准测试,该测试包含了4326个简短、寻求事实的问题。SimpleQA基准测试的设计初衷是针对最新的语言模型,特别是GPT-4,进行对抗性收集,以确保其挑战性。通过这种方式,SimpleQA不仅测试模型的知识边界,还激励研究人员开发出能够更准确、更可靠地提供事实答案的新模型,此外,SimpleQA的易评分性使得研究人员能够快速、准确地评估模型的性能,这为研究社区提供了一个实用的工具,以衡量和比较不同模型在处理简短、事实性问题上的能力。SimpleQA还希望能够对下一代前沿模型保持相关性,成为衡量语言模型在事实性方面进步的重要标准,通过持续挑战和评估模型的能力,SimpleQA旨在促进语言模型在事实性方面的发展,并帮助研究人员识别和解决当前模型在提供准确事实信息方面的局限性。
SimpleQA数据收集分为两个主要阶段。首先,AI训练师(即人类标注者)创建问题和答案对。接着,这些问题由另一名AI训练师独立回答,只有当两位训练师的答案相匹配时,这些问题才会被保留。在创建数据集时,研究人员对问题和答案设定了严格的标准。问题必须具有单一答案,专注于客观知识,并明确答案的范围。例如,问题需要指定“哪个城市”或“哪家公司”,而不是模糊地询问“在哪里”。此外,参考答案答案不应随时间变化,以保持数据集的时效性。所有问题的答案都必须有证据支持,AI训练师在创建问题和答案时需要提供支持答案的网页链接。最后,问题必须足够具有挑战性,至少有四分之一的OpenAI模型回答错误,才能被认为是合适的问题。为了提高AI训练师编写问题的质量,研究人员在问题创建阶段使用了一系列基于少量样本提示的ChatGPT分类器来检测标准违规情况,比如未指定单位、答案随时间变化或存在多个答案,被ChatGPT检测到违规的问题会被退回给AI训练师进行修订。在问题创建阶段结束时,研究人员使用ChatGPT轻微重写问题,以改善语法和标点,而不改变问题的内容。

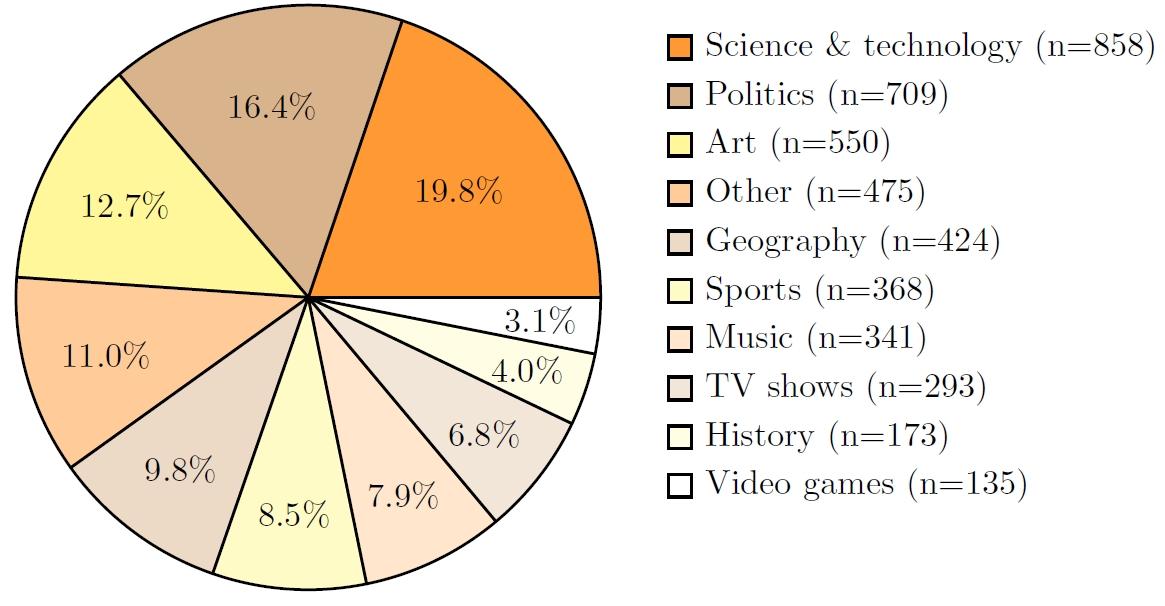
SimpleQA数据集在多样性方面也进行了考量。问题涵盖了广泛的主题,包括历史、科学与技术、艺术、地理、电视节目等,研究人员使用ChatGPT对问题进行事后标记,以统计不同主题的比例。此外,他们还从答案类型和来源的多样性进行了分析,发现答案类型中日期占32.8%,人物占24.1%,数字占15.3%,地点占9.9%,其他占18.0%。在来源方面,wikipedia.com是最大的来源,其次是fandom.com、ac.uk和imdb.com。评分和度量方法方面,研究人员使用基于提示的ChatGPT分类器来评估预测答案,将其评为“正确”、“不正确”或“未尝试”。正确答案是指预测答案完全包含参考答案答案,且不与参考答案答案相矛盾,不正确答案是指预测答案在任何方面与参考答案答案相矛盾,即使是含糊的矛盾,未尝试答案则指参考答案答案没有完全给出,且预测答案中没有与参考答案答案相矛盾的地方。研究人员还提出了一些度量指标,如总体正确率(所有问题中回答正确的百分比)和给定尝试的正确率(在尝试回答的问题中回答正确的百分比)。为了得到一个单一数字的度量指标,研究人员计算了F分数,即总体正确率和给定尝试的正确率的调和平均值。
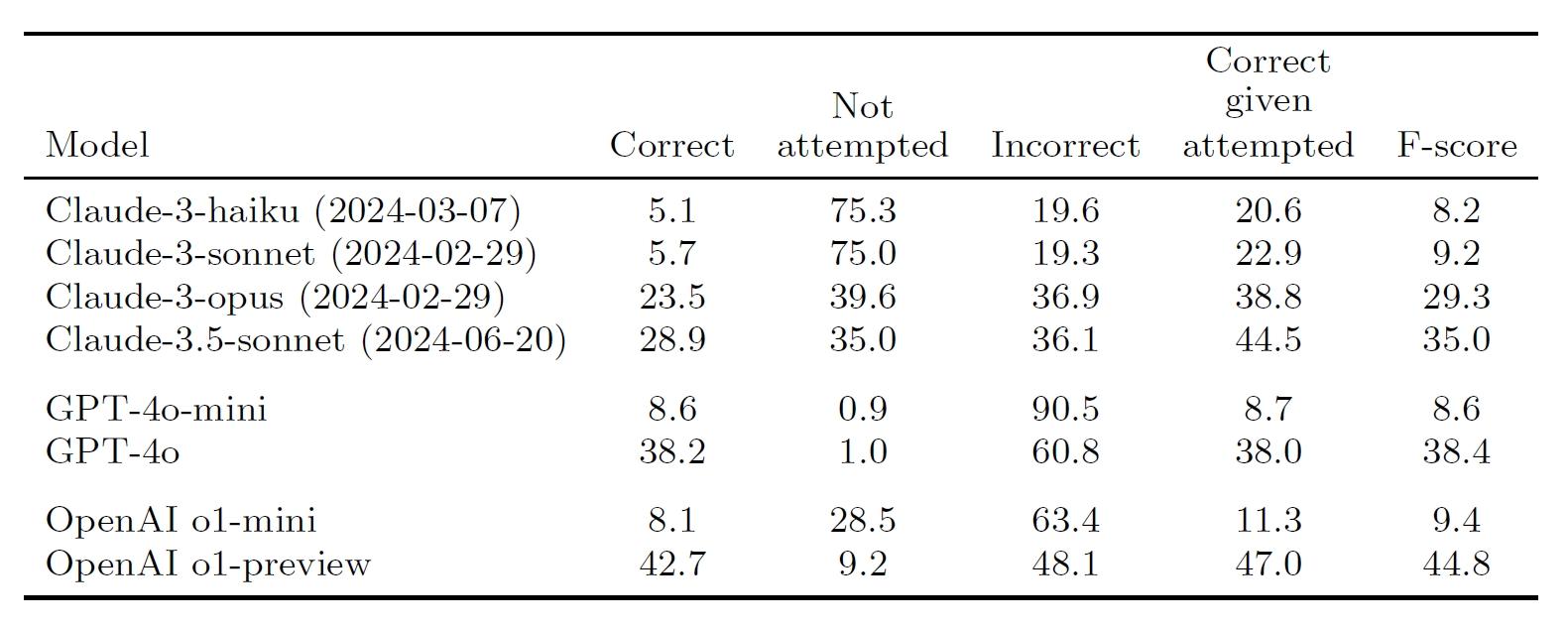
在SimpleQA上,研究人员对一系列OpenAI和Anthropic模型进行了评估,以展示它们在回答简短事实性问题时的性能。这些模型包括不同版本的GPT-4o、GPT-4o-mini、o1-mini、o1-preview以及Claude系列。评估结果显示,较大模型的性能普遍高于较小模型,例如GPT-4o的性能优于GPT-4o-mini。此外,研究人员还发现Claude系列模型在面对问题时更倾向于选择不作答,这可能是它们在F分数上与其他模型相似的原因之一,这些发现表明,SimpleQA作为一个挑战性的基准测试,对于前沿模型来说非常具有挑战性。
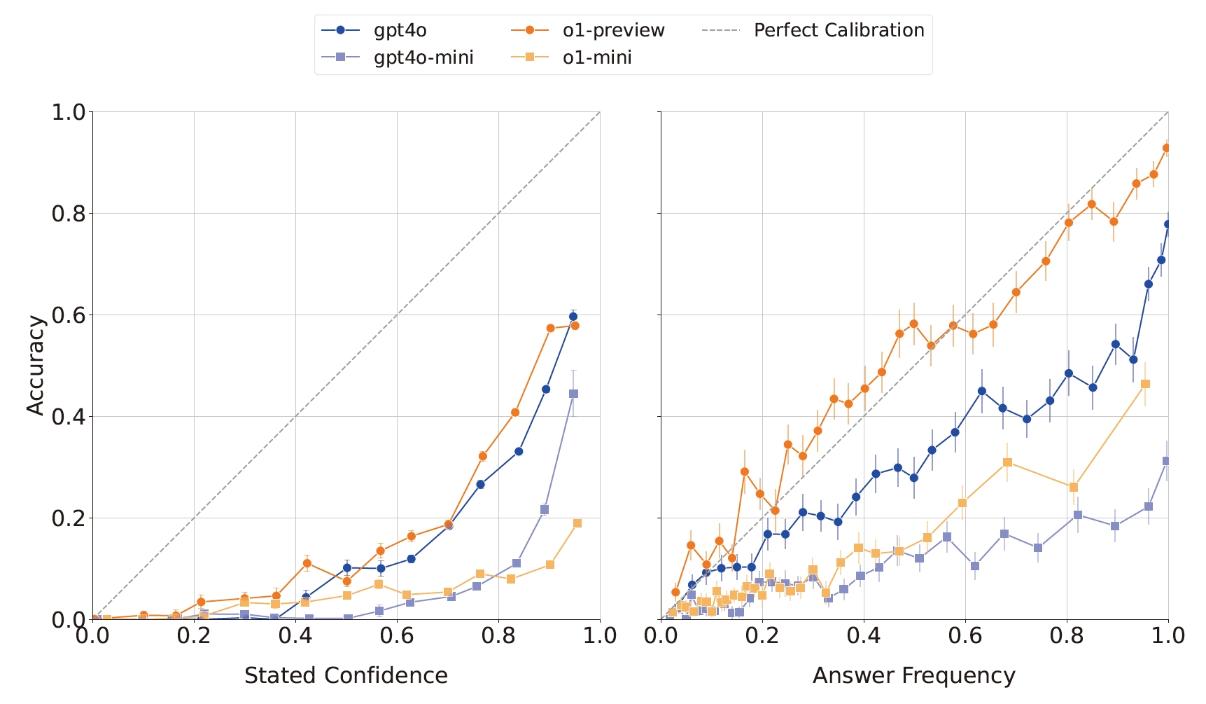
为了测量语言模型的校准,研究人员采用了两种方法。首先,研究人员直接询问语言模型对其答案的信心程度,并将其陈述的信心与实际准确性进行对比。在一个完全校准的模型中,模型的陈述信心与实际准确性应该是一致的,例如,如果模型在所有陈述信心为75%的提示中,其准确性也为75%,那么这个模型就是完全校准的。研究人员的实验结果显示,模型的陈述信心与准确性之间存在正相关,这是一个令人鼓舞的迹象,表明模型对其答案有一定的信心概念。然而,实际性能低于陈述信心的线(y=x)意味着模型普遍高估了自己的信心,表明在提高大型语言模型的校准方面还有很大的改进空间。另一种测量校准的方法是,研究人员对同一个问题向语言模型提问100次,并评估答案的频率是否与其正确性相对应,如果一个模型是校准的,那么答案的频率应该与其准确性大致相等。在研究人员的实验中,研究人员发现所有模型的准确性都随着答案频率的增加而提高,其中o1-preview模型的校准水平最高,其答案的频率大致等同于其准确性,这与基于陈述信心的校准结果一致,再次显示o1-preview比o1-mini更校准,GPT-4o比GPT-4o-mini更校准。这些发现进一步证实了大语言模型在陈述信心方面的校准问题,并指出了通过重复提问来评估模型校准的有效性。
SimpleQA作为一个衡量语言模型事实性的新基准测试,与之前的基准测试相比,具有其独特之处,先前的基准测试,如TriviaQA和Natural Questions,在它们的时代是优秀的数据集,但对当今的语言模型来说已经过于简单。SimpleQA旨在挑战前沿模型,如GPT-4o和Claude,这些模型在SimpleQA上的表现远低于早期基准测试。与TriviaQA和Natural Questions相比,SimpleQA包含了更多元的问题,覆盖了历史、科学与技术、艺术、地理、电视节目等多个领域,并且每个问题都设计为只有一个明确无争议的答案,这使得评估变得更加直接和客观。在语言模型校准方面,这些研究探讨了神经网络是否校准,即模型是否知道自己知道什么,SimpleQA中的一个发现是,答案的频率与准确性相关,此外,也有工作致力于改善语言模型的校准度,这可能促进语言模型在现实世界中的更广泛应用。尽管SimpleQA在准确性方面有所贡献,但其主要局限性在于,它仅在简短、单一可验证答案的事实查询这一受限设置下衡量事实性。SimpleQA是否能够衡量模型在撰写包含众多事实的长篇回应时的能力,仍然是一个未解决的研究问题,因此,SimpleQA可能无法完全代表语言模型在更复杂、更开放的情境下的表现。
 豫公网安备41010702003375号
豫公网安备41010702003375号